WebGPU API
Limited availability
This feature is not Baseline because it does not work in some of the most widely-used browsers.
Experimentell: Dies ist eine experimentelle Technologie
Überprüfen Sie die Browser-Kompatibilitätstabelle sorgfältig vor der Verwendung auf produktiven Webseiten.
Sicherer Kontext: Diese Funktion ist nur in sicheren Kontexten (HTTPS) in einigen oder allen unterstützenden Browsern verfügbar.
Die WebGPU API ermöglicht es Webentwicklern, die GPU (Graphics Processing Unit) des zugrunde liegenden Systems zu nutzen, um leistungsstarke Berechnungen durchzuführen und komplexe Bilder zu zeichnen, die im Browser gerendert werden können.
WebGPU ist der Nachfolger von WebGL und bietet eine bessere Kompatibilität mit modernen GPUs, Unterstützung für allgemeine GPU-Berechnungen, schnellere Abläufe und Zugang zu fortgeschritteneren GPU-Features.
Konzepte und Nutzung
Es lässt sich sagen, dass WebGL das Web in Bezug auf grafische Fähigkeiten revolutionierte, nachdem es erstmals um 2011 erschien. WebGL ist ein JavaScript-Port der OpenGL ES 2.0 Grafiken-Bibliothek, die es Webseiten ermöglicht, Berechnungen direkt an die GPU des Geräts zu übergeben, um diese mit sehr hoher Geschwindigkeit abzuarbeiten und das Ergebnis in einem <canvas>-Element zu rendern.
WebGL und die GLSL Sprache, die zur Erstellung von WebGL-Shadern verwendet wird, sind komplex, daher wurden mehrere WebGL-Bibliotheken entwickelt, die das Erstellen von WebGL-Anwendungen erleichtern: Beliebte Beispiele sind Three.js, Babylon.js und PlayCanvas. Entwickler haben diese Tools genutzt, um immersive webbasiere 3D-Spiele, Musikvideos, Trainings- und Modellierungs-Tools, VR- und AR-Erlebnisse und mehr zu erstellen.
Allerdings hat WebGL einige grundlegende Probleme, die behoben werden mussten:
- Seit der Veröffentlichung von WebGL ist eine neue Generation nativer GPU-APIs aufgetaucht — die populärsten sind Microsoft Direct3D 12, Apple Metal und The Khronos Group Blockly|Vulkan, die eine Vielzahl neuer Funktionen bieten. Es sind keine weiteren Updates für OpenGL (und damit WebGL) geplant, sodass es keine dieser neuen Funktionen mehr erhalten wird. Bei WebGPU hingegen werden künftig neue Funktionen hinzugefügt.
- WebGL konzentriert sich ausschließlich auf das Zeichnen von Grafiken und deren Rendering auf eine Leinwand. Es handhabt allgemeine GPU-Berechnungen (GPGPU) nicht sehr gut. GPGPU-Berechnungen werden für viele verschiedene Anwendungsfälle immer wichtiger, zum Beispiel für diejenigen, die auf maschinellen Lernmodellen basieren.
- 3D-Grafikanwendungen werden zunehmend anspruchsvoller, sowohl in Bezug auf die Anzahl der gleichzeitig zu rendernden Objekte als auch auf die Nutzung neuer Rendering-Funktionen.
WebGPU löst diese Probleme, indem es eine aktualisierte allgemeine Architektur bereitstellt, die mit modernen GPU-APIs kompatibel ist und sich "weborientierter" anfühlt. Es unterstützt das grafische Rendering, bietet jedoch auch erstklassige Unterstützung für GPGPU-Berechnungen. Rendering einzelner Objekte ist auf der CPU-Seite signifikant günstiger, und es unterstützt moderne GPU-Rendering-Funktionen wie berechnungsbasierte Partikel und Nachbearbeitungsfilter wie Farbeffekte, Scharfstellen und Tiefenunschärfesimulation. Zudem kann es aufwendige Berechnungen wie Clipping und Transformation von skinned Models direkt auf der GPU durchführen.
Allgemeines Modell
Zwischen einer Gerät-GPU und einem Webbrowser, der die WebGPU API ausführt, befinden sich mehrere Abstraktionsebenen. Es ist nützlich, diese zu verstehen, wenn man beginnt, WebGPU zu lernen:
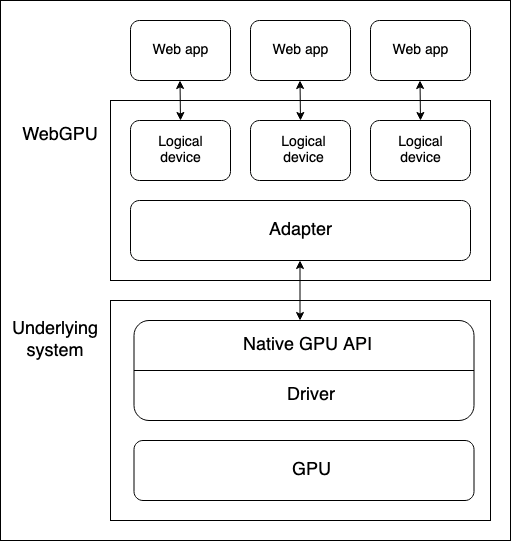
-
Physische Geräte haben GPUs. Die meisten Geräte haben nur eine GPU, aber einige haben mehr als eine. Verschiedene GPU-Typen sind verfügbar:
- Integrierte GPUs, die auf demselben Board wie die CPU leben und deren Speicher teilen.
- Dedizierte GPUs, die auf einem eigenen Board leben, getrennt von der CPU.
- Software-"GPUs", die auf der CPU implementiert sind.
Hinweis: Das obige Diagramm geht von einem Gerät mit nur einer GPU aus.
-
Eine native GPU-API, die Teil des Betriebssystems ist (z.B. Metal auf macOS), ist eine Programmieroberfläche, die es nativen Anwendungen ermöglicht, die Fähigkeiten der GPU zu nutzen. API-Anweisungen werden über einen Treiber an die GPU gesendet (und Antworten empfangen). Es ist möglich, dass ein System mehrere native OS-APIs und Treiber zur Verfügung hat, um mit der GPU zu kommunizieren, obwohl das obige Diagramm von einem Gerät mit nur einer nativen API/Treiber ausgeht.
-
Die WebGPU-Implementierung eines Browsers kümmert sich um die Kommunikation mit der GPU über einen nativen GPU-API-Treiber. Ein WebGPU-Adapter repräsentiert effektiv eine physische GPU und einen Treiber, der im zugrunde liegenden System verfügbar ist, in Ihrem Code.
-
Ein logisches Gerät ist eine Abstraktion, über die eine einzelne Webanwendung auf GPU-Fähigkeiten auf eine segmentierte Weise zugreifen kann. Logische Geräte sind erforderlich, um Multiplex-Fähigkeiten bereitzustellen. Eine GPU eines physischen Geräts wird von vielen Anwendungen und Prozessen gleichzeitig verwendet, inklusive potenziell vieler Webanwendungen. Jede Webanwendung muss in der Lage sein, auf WebGPU isoliert zuzugreifen, aus Sicherheits- und Logikgründen.
Zugriff auf ein Gerät
Ein logisches Gerät — repräsentiert durch eine GPUDevice Objektinstanz — ist die Basis, von der aus eine Webanwendung Zugriff auf die gesamte WebGPU-Funktionalität erhält. Der Zugriff auf ein Gerät erfolgt wie folgt:
- Die
Navigator.gpuEigenschaft (oderWorkerNavigator.gpu, wenn Sie die WebGPU-Funktionalität innerhalb eines Workers nutzen) liefert dasGPUObjekt für den aktuellen Kontext. - Sie greifen über die Methode
GPU.requestAdapter()auf einen Adapter zu. Diese Methode akzeptiert ein optionales Einstellungsobjekt, mit dem Sie beispielsweise einen leistungsstarken oder energieeffizienten Adapter anfordern können. Wenn dies nicht enthalten ist, bietet das Gerät Zugriff auf den Standardadapter, der für die meisten Zwecke ausreichend ist. - Ein Gerät kann über
GPUAdapter.requestDevice()angefordert werden. Diese Methode akzeptiert ebenfalls ein Optionsobjekt (als Deskriptor bezeichnet), das zur Angabe der genauen Merkmale und Grenzen verwendet werden kann, die Sie für das logische Gerät vorsehen. Wenn dies nicht enthalten ist, wird das gelieferte Gerät eine vernünftige allgemeine Spec haben, die für die meisten Zwecke ausreicht.
In Kombination mit einigen Feature-Erkennungsprüfungen könnte der obige Prozess wie folgt erreicht werden:
async function init() {
if (!navigator.gpu) {
throw Error("WebGPU not supported.");
}
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
throw Error("Couldn't request WebGPU adapter.");
}
const device = await adapter.requestDevice();
//...
}
Pipelines und Shader: WebGPU-App-Struktur
Eine Pipeline ist eine logische Struktur, die programmierbare Stufen enthält, die abgeschlossen werden, um die Arbeit Ihres Programms zu erledigen. WebGPU kann derzeit zwei Arten von Pipelines verarbeiten:
-
Eine Rendering-Pipeline rendert Grafiken, typischerweise in ein
<canvas>-Element, kann jedoch auch Grafiken im Offscreen-Modus rendern. Sie hat zwei Hauptstufen:- Eine Vertex-Stufe, in der ein Vertex-Shader Positionierungsdaten entgegennimmt, die in die GPU eingespeist werden, und diese verwendet, um eine Reihe von Vertexen im 3D-Raum durch Anwenden spezifizierter Effekte wie Rotation, Translation oder Perspektive zu positionieren. Die Vertexe werden dann in Primitiven wie Dreiecke (der grundlegende Baustein gerenderter Grafiken) zusammengesetzt und von der GPU rasterisiert, um herauszufinden, welche Pixel jedes bedecken soll.
- Eine Fragmentstufe, in der ein Fragment-Shader die Farbe für jedes Pixel berechnet, das von den in der Vertex-Stufe erzeugten Primitiven abgedeckt wird. Diese Berechnungen verwenden häufig Eingaben wie Bilder (in Form von Texturen), die Oberflächendetails und Position sowie Farbe virtueller Lichter liefern.
-
Eine Berechnungs-Pipeline ist für allgemeine Berechnungen. Eine Berechnungs-Pipeline enthält eine einzige Berechnungsstufe, in der ein Berechnungs-Shader allgemeine Daten entgegennimmt, sie parallel über eine festgelegte Anzahl von Arbeitsgruppen verarbeitet und dann das Ergebnis in einem oder mehreren Puffern zurückgibt. Die Puffer können jede Art von Daten enthalten.
Die oben erwähnten Shader sind Anweisungssets, die von der GPU verarbeitet werden. WebGPU-Shader sind in einer low-level Rust-ähnlichen Sprache namens WebGPU Shader Language (WGSL) geschrieben.
Es gibt verschiedene Möglichkeiten, wie Sie eine WebGPU-App architektonisch gestalten könnten, aber der Prozess wird wahrscheinlich die folgenden Schritte enthalten:
- Shader-Module erstellen: Schreiben Sie Ihren Shader-Code in WGSL und verpacken Sie ihn in einem oder mehreren Shader-Modulen.
- Holen und konfigurieren Sie den Canvas-Kontext: Holen Sie sich den
webgpu-Kontext eines<canvas>-Elements und konfigurieren Sie es, um Informationen darüber zu erhalten, welche Grafiken von Ihrem GPU-logischen-Gerät gerendert werden sollen. Dieser Schritt ist nicht notwendig, wenn Ihre App keine grafische Ausgabe hat, wie etwa eine, die nur Berechnungspipelines verwendet. - Ressourcen erstellen, die Ihre Daten enthalten: Die Daten, die Sie von Ihren Pipelines verarbeiten lassen möchten, müssen in GPU-Puffern oder Texturen gespeichert werden, um von Ihrer App darauf zuzugreifen.
- Pipelines erstellen: Definieren Sie Pipeline-Deskriptoren, die die gewünschten Pipelines im Detail beschreiben, einschließlich der erforderlichen Datenstruktur, Bindungen, Shader und Ressourcendifferenzen, und erstellen Sie Pipelines daraus. Unsere grundlegenden Demos enthalten nur eine einzige Pipeline, aber nicht triviale Apps werden üblicherweise mehrere Pipelines für verschiedene Zwecke enthalten.
- Eine Berechnungs-/Rendering-Pass ausführen: Dies umfasst eine Anzahl von Unter-Schritten:
- Erstellen Sie einen Befehls-Encoder, der eine Reihe von Befehlen an die GPU zum Ausführen übergeben kann.
- Erstellen Sie ein Pass-Encoder-Objekt, auf dem Berechnungs-/Rendering-Befehle ausgegeben werden.
- Führen Sie Befehle aus, um anzugeben, welche Pipelines verwendet werden sollen, aus welchem Puffer (n) die erforderlichen Daten geholt werden sollen, wie viele Zeichenoperationen ausgeführt werden sollen (im Falle von Render-Pipelines) usw.
- Finalisieren Sie die Befehlsliste und kapseln Sie sie in einen Befehls-Puffer ein.
- Übergeben Sie den Befehls-Puffer an die GPU über die Befehlswarteschlange des logischen Geräts.
In den folgenden Abschnitten werden wir uns ein grundlegendes Render-Pipeline-Demo ansehen, um Ihnen die Möglichkeit zu geben, das erforderliche zu erkunden. Später werden wir uns auch ein einfaches Berechnungs-Pipeline-Beispiel ansehen und untersuchen, wie es sich von der Render-Pipeline unterscheidet.
Grundlegende Render-Pipeline
In unserem grundlegenden Render-Demo geben wir einem <canvas>-Element einen einfarbigen blauen Hintergrund und zeichnen ein Dreieck darauf.
Shader-Module erstellen
Wir verwenden den folgenden Shader-Code. Die Vertex-Shader-Stufe (@vertex-Block) akzeptiert ein Datenstück, das eine Position und eine Farbe enthält, positioniert den Vertex entsprechend der gegebenen Position, interpoliert die Farbe und übergibt die Daten an die Fragment-Shader-Stufe. Die Fragment-Shader-Stufe (@fragment-Block) akzeptiert die Daten von der Vertex-Shader-Stufe und färbt den Vertex gemäß der gegebenen Farbe ein.
const shaders = `
struct VertexOut {
@builtin(position) position : vec4f,
@location(0) color : vec4f
}
@vertex
fn vertex_main(@location(0) position: vec4f,
@location(1) color: vec4f) -> VertexOut
{
var output : VertexOut;
output.position = position;
output.color = color;
return output;
}
@fragment
fn fragment_main(fragData: VertexOut) -> @location(0) vec4f
{
return fragData.color;
}
`;
Hinweis:
In unseren Demos speichern wir unseren Shader-Code in einer Template-Literal, aber Sie können ihn überall speichern, von wo aus es einfach als Text abgerufen werden kann, um in Ihr WebGPU-Programm eingespeist zu werden. Ein anderer gängiger Ansatz ist es, Shader in einem <script>-Element zu speichern und die Inhalte mit Node.textContent abzurufen. Der korrekte MIME-Typ für WGSL ist text/wgsl.
Um Ihren Shader-Code für WebGPU verfügbar zu machen, müssen Sie ihn in ein GPUShaderModule über einen GPUDevice.createShaderModule() Aufruf packen und Ihren Shader-Code als Eigenschaft in einem Deskriptor-Objekt übergeben, zum Beispiel:
const shaderModule = device.createShaderModule({
code: shaders,
});
Canvas-Kontext abrufen und konfigurieren
In einer Render-Pipeline müssen wir angeben, wo die Grafiken gerendert werden sollen. In diesem Fall holen wir eine Referenz auf ein Onscreen-<canvas>-Element und rufen HTMLCanvasElement.getContext() mit einem Parameter von webgpu auf, um den GPU-Kontext (eine GPUCanvasContext Instanz) zurückzugeben.
Von dort konfigurieren wir den Kontext mit einem Aufruf von GPUCanvasContext.configure(), indem wir ein Optionen-Objekt übergeben, das das GPUDevice, aus dem die Rendering-Informationen stammen werden, das Format, das die Texturen haben werden, und den Alpha-Modus, der beim Rendern halbtransparenter Texturen verwendet werden soll, enthält.
const canvas = document.querySelector("#gpuCanvas");
const context = canvas.getContext("webgpu");
context.configure({
device: device,
format: navigator.gpu.getPreferredCanvasFormat(),
alphaMode: "premultiplied",
});
Hinweis:
Die beste Praxis zur Bestimmung des Texturformats ist die Verwendung der Methode GPU.getPreferredCanvasFormat(); dies wählt das effizienteste Format (entweder bgra8unorm oder rgba8unorm) für das Gerät des Benutzers aus.
Einen Buffer erstellen und unsere Dreiecks-Daten hineinschreiben
Als nächstes stellen wir unserem WebGPU-Programm unsere Daten in einer Form zur Verfügung, die es verwenden kann. Unsere Daten werden initial in einem Float32Array bereitgestellt, das 8 Datenpunkte für jeden Dreiecks-Vertex enthält — X, Y, Z, W für die Position und R, G, B, A für die Farbe.
const vertices = new Float32Array([
0.0, 0.6, 0, 1, 1, 0, 0, 1, -0.5, -0.6, 0, 1, 0, 1, 0, 1, 0.5, -0.6, 0, 1, 0,
0, 1, 1,
]);
Wir haben jedoch ein Problem. Wir müssen unsere Daten in einen GPUBuffer bekommen. Hinter den Kulissen wird dieser Puffer in einem Speicher gespeichert, der sehr eng in die Kerne der GPU integriert ist, um die gewünschte Hochleistungsverarbeitung zu ermöglichen. Ein Nebeneffekt davon ist, dass dieser Speicher von Prozessen, die auf dem Host-System laufen, wie z.B. dem Browser, nicht zugänglich ist.
Der GPUBuffer wird über einen Aufruf von GPUDevice.createBuffer() erstellt. Wir geben ihm eine Größe, die der Länge des vertices-Arrays entspricht, damit es alle Daten enthalten kann, sowie die VERTEX- und COPY_DST-Verwendungs-Flags, um anzuzeigen, dass der Puffer als Vertex-Puffer und als Ziel von Kopieroperationen verwendet wird.
const vertexBuffer = device.createBuffer({
size: vertices.byteLength, // make it big enough to store vertices in
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
Wir könnten das Einfügen der Daten in den GPUBuffer mit einer Mapping-Operation handhaben, wie wir im Beispiel der Berechnungs-Pipeline verwenden, um Daten von der GPU zurück zu JavaScript zu lesen. In diesem Fall verwenden wir jedoch die praktische GPUQueue.writeBuffer() Komfortmethode, die als Parameter den Puffer angibt, in den geschrieben werden soll, die Datenquelle, aus der geschrieben wird, ein Offset-Wert für jeden, sowie die zu schreibende Datenmenge (wir haben die gesamte Länge des Arrays angegeben). Der Browser ermittelt dann, wie die Daten auf effizienteste Weise geschrieben werden können.
device.queue.writeBuffer(vertexBuffer, 0, vertices, 0, vertices.length);
Definieren und Erstellen der Render-Pipeline
Jetzt, da wir unsere Daten in einen Puffer haben, ist der nächste Teil des Setups tatsächlich das Erstellen unserer Pipeline, damit sie für das Rendering verwendet werden kann.
Zuerst erstellen wir ein Objekt, das das erforderliche Layout unserer Vertex-Daten beschreibt. Es beschreibt perfekt, was wir zuvor in unserem vertices-Array und der Vertex-Shader-Stufe gesehen haben — jeder Vertex hat Position- und Farbdaten. Beide sind im float32x4-Format formatiert (was dem WGSL vec4<f32>-Typ entspricht), und die Farbdaten beginnen bei einem Offset von 16 Bytes in jedem Vertex. arrayStride gibt den Abstand an, was bedeutet, die Anzahl der Bytes, die jeden Vertex ausmachen, und stepMode gibt an, dass die Daten pro-Vertex abgerufen werden sollen.
const vertexBuffers = [
{
attributes: [
{
shaderLocation: 0, // position
offset: 0,
format: "float32x4",
},
{
shaderLocation: 1, // color
offset: 16,
format: "float32x4",
},
],
arrayStride: 32,
stepMode: "vertex",
},
];
Als nächstes erstellen wir ein Deskriptor-Objekt, das die Konfiguration unserer Render-Pipeline-Stufen spezifiziert. Für beide Shader-Stufen spezifizieren wir das GPUShaderModule, in dem der relevante Code gefunden werden kann (shaderModule), und den Namen der Funktion, die als Einstiegspunkt für jede Stufe dient.
Darüber hinaus, im Fall der Vertex-Shader-Stufe stellen wir unser vertexBuffers-Objekt bereit, um den erwarteten Zustand unserer Vertex-Daten bereitzustellen. Und im Fall unserer Fragment-Shader-Stufe stellen wir ein Array von Farbzielzuständen bereit, das das angegebene Rendering-Format angibt (dies entspricht dem Format, das zuvor in unserer Canvas-Kontext-Konfiguration angegeben wurde).
Wir spezifizieren auch einen primitive-Zustand, der in diesem Fall nur den Typ des Primitivs angibt, das wir zeichnen werden, und ein layout von auto. Die layout-Eigenschaft definiert das Layout (Struktur, Zweck und Typ) aller GPU-Ressourcen (Puffer, Texturen usw.), die während der Ausführung der Pipeline verwendet werden. In komplexeren Apps würde dies in Form eines GPUPipelineLayout Objekts vorkommen, erstellt mit GPUDevice.createPipelineLayout() (Sie können ein Beispiel in unserer Basic compute pipeline sehen), das der GPU ermöglicht, herauszufinden, wie die Pipeline im Voraus am effizientesten ausgeführt wird. Hier jedoch geben wir den Wert auto an, was dazu führt, dass die Pipeline ein implizites Bindungsgruppen-Layout basierend auf allen in den Shader-Code definierten Bindungen generiert.
const pipelineDescriptor = {
vertex: {
module: shaderModule,
entryPoint: "vertex_main",
buffers: vertexBuffers,
},
fragment: {
module: shaderModule,
entryPoint: "fragment_main",
targets: [
{
format: navigator.gpu.getPreferredCanvasFormat(),
},
],
},
primitive: {
topology: "triangle-list",
},
layout: "auto",
};
Schließlich können wir eine GPURenderPipeline basierend auf unserem pipelineDescriptor-Objekt erstellen, indem wir es als Parameter an einen Aufruf von GPUDevice.createRenderPipeline() übergeben.
const renderPipeline = device.createRenderPipeline(pipelineDescriptor);
Eine Rendering-Pass ausführen
Nachdem das gesamte Setup abgeschlossen ist, können wir tatsächlich eine Rendering-Pass ausführen und etwas auf unser <canvas> zeichnen. Um Befehle zu codieren, die später an die GPU ausgegeben werden sollen, müssen Sie eine GPUCommandEncoder Instanz erstellen, was mit einem GPUDevice.createCommandEncoder() Aufruf erfolgt.
const commandEncoder = device.createCommandEncoder();
Als nächstes starten wir den Rendering-Pass, indem wir eine GPURenderPassEncoder Instanz mit einer GPUCommandEncoder.beginRenderPass() Aufruf erstellen. Diese Methode nimmt ein Deskriptor-Objekt als Parameter an, wobei die einzige obligatorische Eigenschaft ein colorAttachments-Array ist. In diesem Fall geben wir an:
- Eine Texturansicht, in die gerendert werden soll; wir erstellen eine neue Ansicht aus dem
<canvas>übercontext.getCurrentTexture().createView(). - Dass die Ansicht auf eine bestimmte Farbe "gelöscht" werden soll, nachdem sie geladen wurde und bevor irgendwelche Zeichnungen stattfinden. Dies ist das, was den blauen Hintergrund hinter dem Dreieck verursacht.
- Dass der Wert des aktuellen Rendering-Passes für diesen Farbattachement gespeichert werden soll.
const clearColor = { r: 0.0, g: 0.5, b: 1.0, a: 1.0 };
const renderPassDescriptor = {
colorAttachments: [
{
clearValue: clearColor,
loadOp: "clear",
storeOp: "store",
view: context.getCurrentTexture().createView(),
},
],
};
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
Jetzt können wir Methoden des Rendering-Pass-Encoders aufrufen, um unser Dreieck zu zeichnen:
GPURenderPassEncoder.setPipeline()wird mit unseremrenderPipeline-Objekt als Parameter aufgerufen, um die für den Rendering-Pass zu verwendende Pipeline anzugeben.GPURenderPassEncoder.setVertexBuffer()wird mit unseremvertexBuffer-Objekt als Parameter aufgerufen, um als Datenquelle zu dienen, die an die Pipeline übergeben wird, um gerendert zu werden. Der erste Parameter ist der Slot, um den Vertex-Puffer einzustellen, und ist ein Verweis auf den Index des Elements imvertexBuffers-Array, der das Layout dieses Puffers beschreibt.GPURenderPassEncoder.draw()setzt das Zeichnen in Bewegung. Es gibt Daten für drei Vertexe in unseremvertexBuffer, daher setzen wir einen Vertexanzahlenwert von3, um sie alle zu zeichnen.
passEncoder.setPipeline(renderPipeline);
passEncoder.setVertexBuffer(0, vertexBuffer);
passEncoder.draw(3);
Um die Befehlssequenz zu beenden und sie an die GPU auszugeben, sind drei weitere Schritte erforderlich.
- Wir rufen die Methode
GPURenderPassEncoder.end()auf, um das Ende der Render-Pass-Befehlsliste zu signalisieren. - Wir rufen die Methode
GPUCommandEncoder.finish()auf, um die Aufnahme der ausgegebenen Befehlssequenz abzuschließen und sie in einGPUCommandBufferObjektinstanz zu kapseln. - Wir übergeben den
GPUCommandBufferan die Befehlswarteschlange des Geräts (repräsentiert durch eineGPUQueueInstanz), um an die GPU gesendet zu werden. Die Befehlswarteschlange des Geräts ist über dieGPUDevice.queueEigenschaft verfügbar, und ein Array vonGPUCommandBufferInstanzen kann über einen Aufruf vonGPUQueue.submit()der Warteschlange hinzugefügt werden.
Diese drei Schritte können mit den folgenden zwei Zeilen erreicht werden:
passEncoder.end();
device.queue.submit([commandEncoder.finish()]);
Grundlegende Berechnungs-Pipeline
In unserem grundlegenden Berechnungs-Demo lassen wir die GPU einige Werte berechnen, sie in einem Ausgabepuffer speichern, die Daten in einen Staging-Puffer kopieren und dann den Staging-Puffer so mappen, dass die Daten zurück an JavaScript gelesen und in der Konsole protokolliert werden können.
Die App folgt einer ähnlichen Struktur wie das Grundlagen-Rendering-Demo. Wir erstellen eine GPUDevice Referenz auf die gleiche Weise wie zuvor, und kapseln unseren Shader-Code in ein GPUShaderModule über einen GPUDevice.createShaderModule() Aufruf. Der Unterschied hier ist, dass unser Shader-Code nur eine Shader-Stufe hat, eine @compute Stufe:
// Define global buffer size
const NUM_ELEMENTS = 1000;
const BUFFER_SIZE = NUM_ELEMENTS * 4; // Buffer size, in bytes
const shader = `
@group(0) @binding(0)
var<storage, read_write> output: array<f32>;
@compute @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3u,
@builtin(local_invocation_id)
local_id : vec3u,
) {
// Avoid accessing the buffer out of bounds
if (global_id.x >= ${NUM_ELEMENTS}) {
return;
}
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
}
`;
Puffer zur Handhabung unserer Daten erstellen
In diesem Beispiel erstellen wir zwei GPUBuffer Instanzen, um unsere Daten zu handhaben, einen output Puffer, um die GPU-Berechnungsergebnisse mit hoher Geschwindigkeit zu schreiben, und einen stagingBuffer, in den wir den Inhalt von output kopieren, der gemappt werden kann, um JavaScript den Zugriff auf die Werte zu ermöglichen.
outputist als Speicherpuffer angegeben, der die Quelle einer Kopieroperation sein wird.stagingBufferist als Puffer angegeben, der für das Lesen durch JavaScript gemappt werden kann und das Ziel einer Kopieroperation sein wird.
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
});
Eine Bindungsgruppen-Layout erstellen
Wenn die Pipeline erstellt wird, geben wir eine Bindungsgruppe an, die für die Pipeline verwendet wird. Dies beinhaltet zuerst das Erstellen eines GPUBindGroupLayout (über einen Aufruf von GPUDevice.createBindGroupLayout()), das die Struktur und den Zweck von GPU-Ressourcen wie Puffern definiert, die in dieser Pipeline verwendet werden sollen. Dieses Layout dient als Vorlage, an die sich Bindungsgruppen halten müssen. In diesem Fall geben wir der Pipeline Zugriff auf einen einzigen Speicherpuffer, der an den Bindungsslot 0 gebunden ist (dies entspricht der relevanten Bindungsnummer im Shader-Code — @binding(0)), nutzbar in der Berechnungsstufe der Pipeline, und mit dem Zweck des Puffers als storage definiert.
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
},
},
],
});
Als nächstes erstellen wir eine GPUBindGroup, indem wir GPUDevice.createBindGroup() aufrufen. Wir übergeben diesem Methodenaufruf ein Deskriptor-Objekt, das das Bindungsgruppen-Layout spezifiziert, auf dem diese Bindungsgruppe basieren soll, und die Details der Variablen, die an den im Layout definierten Slot gebunden werden soll. In diesem Fall deklarieren wir Bindung 0 und spezifizieren, dass der zuvor definierte output Puffer daran gebunden werden soll.
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: output,
},
},
],
});
Hinweis:
Sie könnten ein implizites Layout abrufen, um es beim Erstellen einer Bindungsgruppe zu verwenden, indem Sie die Methode GPUComputePipeline.getBindGroupLayout() aufrufen. Es gibt auch eine Version für Render-Pipelines: siehe GPURenderPipeline.getBindGroupLayout().
Eine Berechnungs-Pipeline erstellen
Mit dem, was oben beschrieben wurde, können wir nun eine Berechnungs-Pipeline erstellen, indem wir GPUDevice.createComputePipeline() aufrufen und ein Pipeline-Deskriptor-Objekt übergeben. Dies funktioniert auf ähnliche Weise wie das Erstellen einer Render-Pipeline. Wir beschreiben den Berechnungs-Shader, spezifizieren, in welchem Modul der Code zu finden ist und welcher Einstiegspunkt verwendet wird. Wir spezifizieren auch ein layout für die Pipeline, in diesem Fall ein Layout basierend auf dem zuvor definierten bindGroupLayout über ein GPUDevice.createPipelineLayout() Aufruf erstellen.
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout],
}),
compute: {
module: shaderModule,
entryPoint: "main",
},
});
Ein Unterschied hier zum Layout der Render-Pipeline ist, dass wir keinen primitiven Typ angeben, da wir nichts zeichnen.
Eine Berechnungs-Pass ausführen
Das Ausführen einer Berechnungs-Pass ist in seiner Struktur ähnlich wie das Ausführen einer Rendering-Pass, mit einigen anderen Befehlen. Der Pass-Encoder wird beispielsweise durch einen Aufruf von GPUCommandEncoder.beginComputePass() erstellt.
Beim Ausgeben der Befehle geben wir die Pipeline auf die gleiche Weise wie zuvor mittels GPUComputePassEncoder.setPipeline() an. Dann verwenden wir jedoch GPUComputePassEncoder.setBindGroup(), um anzugeben, dass wir unsere bindGroup verwenden möchten, um die Daten anzugeben, die in der Berechnung verwendet werden, und GPUComputePassEncoder.dispatchWorkgroups(), um die Anzahl der GPU-Arbeitsgruppen anzugeben, die für die Durchführung der Berechnungen verwendet werden sollen.
Wir signalisieren dann das Ende der Render-Pass-Befehlsliste mit GPURenderPassEncoder.end().
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups(Math.ceil(NUM_ELEMENTS / 64));
passEncoder.end();
Die Ergebnisse zurück an JavaScript lesen
Bevor die codierten Befehle mittels GPUQueue.submit() zur Ausführung an die GPU übergeben werden, kopieren wir die Inhalte des output Puffers in den stagingBuffer-Puffer mit GPUCommandEncoder.copyBufferToBuffer().
// Copy output buffer to staging buffer
commandEncoder.copyBufferToBuffer(
output,
0, // Source offset
stagingBuffer,
0, // Destination offset
BUFFER_SIZE, // Length, in bytes
);
// End frame by passing array of command buffers to command queue for execution
device.queue.submit([commandEncoder.finish()]);
Sobald die Ausgabendaten im stagingBuffer verfügbar sind, verwenden wir die Methode GPUBuffer.mapAsync(), um die Daten in den Zwischenspeicher zu mappen, greifen mit GPUBuffer.getMappedRange() auf den gemappten Bereich zu, kopieren die Daten nach JavaScript und protokollieren sie in der Konsole. Wir nehmen auch die Zwischenspeicherung des stagingBuffer zurück, nachdem wir fertig sind.
// map staging buffer to read results back to JS
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // Offset
BUFFER_SIZE, // Length, in bytes
);
const copyArrayBuffer = stagingBuffer.getMappedRange(0, BUFFER_SIZE);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
console.log(new Float32Array(data));
GPU Fehlerbehandlung
WebGPU-Aufrufe werden asynchron im GPU-Prozess validiert. Wenn Fehler gefunden werden, wird der problematische Aufruf auf der GPU-Seite als ungültig markiert. Wenn ein weiterer Aufruf erfolgt, der von dem Rückgabewert eines ungültig gemachten Aufrufs abhängt, wird auch dieses Objekt als ungültig markiert, und so weiter. Aus diesem Grund werden Fehler in WebGPU als „ansteckend“ bezeichnet.
Jede GPUDevice Instanz verwaltet ihre eigene Fehlerbereichs-Stapelspeicherstruktur. Dieser Stapelspeicher ist anfangs leer, aber Sie können beginnen, einen Fehlerbereich in den Stapel zu schieben, indem Sie GPUDevice.pushErrorScope() aufrufen, um Fehler eines bestimmten Typs zu erfassen.
Wenn Sie mit der Erfassung von Fehlern fertig sind, können Sie die Erfassung beenden, indem Sie GPUDevice.popErrorScope() aufrufen. Dies entnimmt den Bereich aus dem Stapel und gibt ein Promise zurück, das sich zu einem Objekt (GPUInternalError, GPUOutOfMemoryError oder GPUValidationError) zur Beschreibung des ersten im Bereich erfassten Fehlers auflöst oder null, wenn keine Fehler erfasst wurden.
Wir haben versucht, nützliche Informationen bereitzustellen, die Ihnen helfen, zu verstehen, warum Fehler in Ihrem WebGPU-Code auftreten, in "Validierung"-Abschnitten, wo immer angebracht, die Kriterien auflisten, um Fehler zu vermeiden. Siehe zum Beispiel den GPUDevice.createBindGroup() Validierungsabschnitt. Einige dieser Informationen sind komplex; anstatt die Spezifikation zu wiederholen, haben wir uns entschieden, nur Fehlerkriterien aufzulisten, die:
- Nicht offensichtlich sind, zum Beispiel Kombinationen von Deskriptor-Eigenschaften, die Validierungsfehler erzeugen. Es hat dazu keinen Zweck, Ihnen zu sagen, dass Sie sich an die richtige Deskriptor-Objektstruktur halten sollen. Das ist sowohl offensichtlich als auch vage.
- Entwicklern kontrollierbar sind. Einige der Fehlerkriterien sind rein intern basierend und für Webentwickler nicht wirklich von Belang.
Weitere Informationen zur Fehlerbehandlung in WebGPU finden Sie im Informatorium — siehe Object validity and destroyed-ness und Errors. WebGPU Fehlerbehandlungs-Best-Practices bietet nützliche praxisnahe Beispiele und Ratschläge.
Hinweis:
Der historische Weg, Fehler in WebGL zu behandeln, besteht darin, eine getError() Methode bereitzustellen, um Fehlerinformationen zurückzugeben. Dies ist problematisch, da sie Fehler synchron zurückgibt, was schlecht für die Leistung ist — jeder Aufruf erfordert eine Hin- und Rückfahrt zur GPU und erfordert, dass alle zuvor ausgegebenen Vorgänge abgeschlossen werden. Sein Zustandsmodell ist auch flach, was bedeutet, dass Fehler zwischen nicht verwandtem Code durchsickern können. Die Ersteller von WebGPU waren entschlossen, dies zu verbessern.
Schnittstellen
Einstiegspunkt für die API
-
Der Einstiegspunkt für die API — gibt das
GPUObjekt für den aktuellen Kontext zurück. GPU-
Der Ausgangspunkt für die Verwendung von WebGPU. Es kann verwendet werden, um einen
GPUAdapterzurückzugeben. GPUAdapter-
Repräsentiert einen GPU-Adapter. Von hier aus können Sie ein
GPUDevice, Adapter-Infos, Funktionen und Grenzen anfordern. GPUAdapterInfo-
Enthält identifizierende Informationen über einen Adapter.
Konfigurieren von GPUDevices
GPUDevice-
Repräsentiert ein logisches GPU-Gerät. Dies ist die Hauptschnittstelle, über die der Großteil der WebGPU-Funktionalität zugänglich ist.
GPUSupportedFeatures-
Ein setlike Objekt, das zusätzliche Funktionen beschreibt, die von einem
GPUAdapteroderGPUDeviceunterstützt werden. GPUSupportedLimits-
Beschreibt die Grenzen, die von einem
GPUAdapteroderGPUDeviceunterstützt werden.
Konfigurieren eines Rendering-<canvas>
HTMLCanvasElement.getContext()— der"webgpu"contextType-
Ein
getContext()-Aufruf mit dem"webgpu"contextTypegibt einGPUCanvasContextObjektinstanz zurück, das mitGPUCanvasContext.configure()konfiguriert werden kann. GPUCanvasContext-
Repräsentiert den WebGPU-Rendering-Kontext eines
<canvas>Elements.
Pipeline-Ressourcen darstellen
GPUBuffer-
Repräsentiert einen Speicherblock, der dazu verwendet werden kann, Rohdaten zu speichern, die in GPU-Operationen verwendet werden sollen.
GPUExternalTexture-
Ein Wrapper-Objekt, das einen Snapshot eines
HTMLVideoElemententhält, der als Textur in GPU-Rendering-Operationen verwendet werden kann. GPUSampler-
Kontrolliert, wie Shader Texturressourcendaten transformieren und filtern.
GPUShaderModule-
Eine Referenz auf ein internes Shader-Modulobjekt, einen Container für WGSL-Shader-Code, der der GPU zur Ausführung durch eine Pipeline zugewiesen werden kann.
GPUTexture-
Ein Container, der verwendet wird, um 1D-, 2D- oder 3D-Datenarrays wie Bilder zu speichern, die in GPU-Rendering-Operationen verwendet werden.
GPUTextureView-
Eine Ansicht auf einige Teilmengen der von einer bestimmten
GPUTexturedefinierten Textur-Unterressourcen.
Pipelines repräsentieren
GPUBindGroup-
Basierend auf einem
GPUBindGroupLayoutdefiniert eineGPUBindGroupeine Gruppe von Ressourcen, die zusammengefasst werden sollen, und wie diese Ressourcen in Shader-Stufen verwendet werden. GPUBindGroupLayout-
Definiert die Struktur und den Zweck verwandter GPU-Ressourcen wie Puffer, die in einer Pipeline verwendet werden sollen, und wird als Vorlage bei der Erstellung von
GPUBindGroups verwendet. GPUComputePipeline-
Kontrolliert die Berechnungs-Shader-Stufe und kann in einem
GPUComputePassEncoderverwendet werden. GPUPipelineLayout-
Definiert die
GPUBindGroupLayouts, die in einer Pipeline verwendet werden.GPUBindGroups, die während der Befehlscodierung mit der Pipeline verwendet werden, müssen kompatibleGPUBindGroupLayouts haben. GPURenderPipeline-
Kontrolliert die Vertex- und Fragment-Shader-Stufen und kann in einem
GPURenderPassEncoderoderGPURenderBundleEncoderverwendet werden.
Befehle an die GPU kodieren und übermitteln
GPUCommandBuffer-
Repräsentiert eine aufgezeichnete Liste von GPU-Befehlen, die einer
GPUQueuezur Ausführung übergeben werden können. GPUCommandEncoder-
Repräsentiert einen Befehlscodierer, der zum Kodieren von Befehlen verwendet wird, die an die GPU ausgegeben werden sollen.
GPUComputePassEncoder-
Kodiert Befehle im Zusammenhang mit der Steuerung der Berechnungs-Shader-Stufe, wie sie von einer
GPUComputePipelineausgegeben werden. Teil der gesamten Codierungsaktivität einesGPUCommandEncoder. GPUQueue-
Steuert die Ausführung von codierten Befehlen auf der GPU.
GPURenderBundle-
Ein Container für voraufgezeichnete Bündel von Befehlen (siehe
GPURenderBundleEncoder). GPURenderBundleEncoder-
Wird verwendet, um Bündel von Befehlen voraufzuzeichnen. Diese können in
GPURenderPassEncoderbeliebig oft ausgeführt werden. GPURenderPassEncoder-
Kodiert Befehle im Zusammenhang mit der Steuerung der Vertex- und Fragment-Shader-Stufen, wie sie von einer
GPURenderPipelineausgegeben werden. Teil der gesamten Codierungsaktivität einesGPUCommandEncoder.
Abfragen von Rendering-Durchgängen ausführen
GPUQuerySet-
Wird verwendet, um die Ergebnisse von Abfragen bei Durchgängen zu erfassen, wie Okklusions- oder Zeitstempel-Abfragen.
Fehler debuggen
GPUCompilationInfo-
Ein Array von
GPUCompilationMessageObjekten, die vom GPU-Shader-Modul-Kompiler generiert werden, um Probleme mit Shader-Code zu diagnostizieren. GPUCompilationMessage-
Repräsentiert eine einzelne Informations-, Warn- oder Fehlermeldung, die vom GPU-Shader-Modul-Kompiler generiert wird.
GPUDeviceLostInfo-
Wird zurückgegeben, wenn das
GPUDevice.lostPromiseaufgelöst wird und Informationen darüber bereitstellt, warum das Gerät verloren gegangen ist. GPUError-
Die Basisschnittstelle für Fehler, die von
GPUDevice.popErrorScopeund demuncapturederrorEreignis offengelegt werden. GPUInternalError-
Einer der Fehlertypen, die von
GPUDevice.popErrorScopeund demGPUDeviceuncapturederrorEreignis offengelegt werden. Zeigt an, dass ein Vorgang aus einem system- oder implementierungsspezifischen Grund fehlgeschlagen ist, auch wenn alle Validierungsanforderungen erfüllt wurden. GPUOutOfMemoryError-
Einer der Fehlertypen, die von
GPUDevice.popErrorScopeund demGPUDeviceuncapturederrorEreignis offengelegt werden. Zeigt an, dass nicht genügend freier Speicher vorhanden war, um den angeforderten Vorgang abzuschließen. GPUPipelineError-
Beschreibt einen Pipeline-Fehler. Der Wert, der empfangen wird, wenn ein
Promise, das von einemGPUDevice.createComputePipelineAsync()oderGPUDevice.createRenderPipelineAsync()Aufruf zurückgegeben wird, ablehnt. GPUUncapturedErrorEvent-
Der Ereignisobjekt-Typ für das
GPUDeviceuncapturederrorEreignis. GPUValidationError-
Einer der Fehlertypen, die von
GPUDevice.popErrorScopeund demGPUDeviceuncapturederrorEreignis offengelegt werden. Beschreibt einen Anwendungsfehler, der darauf hinweist, dass ein Vorgang die Validierungsbeschränkungen der WebGPU-API nicht eingehalten hat.
Sicherheitsanforderungen
Die gesamte API ist nur in einem sicheren Kontext verfügbar.
Beispiele
Spezifikationen
| Specification |
|---|
| WebGPU # gpu-interface |
Browser-Kompatibilität
BCD tables only load in the browser