Express Tutorial Teil 3: Verwendung einer Datenbank (mit Mongoose)
Dieser Artikel bietet einen kurzen Überblick über Datenbanken und wie sie mit Node/Express-Anwendungen verwendet werden. Anschließend wird gezeigt, wie wir Mongoose einsetzen können, um Datenbankzugriff für die LocalLibrary Website bereitzustellen. Es wird erklärt, wie Objektschema und -modelle deklariert werden, die wichtigsten Feldtypen und grundlegende Validierung. Außerdem werden kurz einige der Hauptmethoden vorgestellt, mit denen Sie auf Modelldaten zugreifen können.
| Voraussetzungen: | Express Tutorial Teil 2: Erstellen einer Grundstruktur für die Website |
|---|---|
| Ziel: | In der Lage sein, Ihre eigenen Modelle mit Mongoose zu entwerfen und zu erstellen. |
Überblick
Bibliothekspersonal wird die Local Library Website nutzen, um Informationen über Bücher und Ausleiher zu speichern, während Bibliotheksmitglieder sie nutzen werden, um nach Büchern zu stöbern und zu suchen, herauszufinden, ob Exemplare verfügbar sind und diese dann zu reservieren oder auszuleihen. Um Informationen effizient zu speichern und abzurufen, werden wir sie in einer Datenbank speichern.
Express-Anwendungen können viele verschiedene Datenbanken verwenden, und es gibt mehrere Ansätze, die Sie für Create (Erstellen), Read (Lesen), Update (Aktualisieren) und Delete (Löschen) (CRUD) Operationen verwenden können. Dieses Tutorial gibt einen kurzen Überblick über einige der verfügbaren Optionen und zeigt dann im Detail die ausgewählten Mechanismen.
Welche Datenbanken kann ich verwenden?
Express Anwendungen können jede Datenbank verwenden, die von Node unterstützt wird (Express selbst definiert keine spezifischen zusätzlichen Verhaltensweisen/Anforderungen für das Datenbankmanagement). Es gibt viele beliebte Optionen, darunter PostgreSQL, MySQL, Redis, SQLite und MongoDB.
Bei der Auswahl einer Datenbank sollten Sie Dinge wie Produktivitätszeit/Lernkurve, Leistung, Replizierbarkeit/Backup-Fähigkeit, Kosten, Community-Unterstützung usw. berücksichtigen. Obwohl es keine einzige "beste" Datenbank gibt, sollten fast alle der populären Lösungen für eine kleine bis mittelgroße Website wie unsere Local Library mehr als ausreichend sein.
Für weitere Informationen zu den Optionen siehe Datenbankintegration (Express-Dokumentation).
Was ist der beste Weg, um mit einer Datenbank zu interagieren?
Es gibt zwei gängige Ansätze, um mit einer Datenbank zu interagieren:
- Verwenden der nativen Abfragesprache der Datenbank, wie SQL.
- Verwendung eines Object Relational Mappers (ORM) oder Object Document Mapper (ODM). Diese stellen die Daten der Website als JavaScript-Objekte dar, die dann auf die zugrunde liegende Datenbank abgebildet werden. Einige ORMs und ODMs sind an eine bestimmte Datenbank gebunden, während andere eine datenbankunabhängige Backend-Lösung bieten.
Die beste Leistung kann erreicht werden, indem SQL verwendet wird oder welche Abfragesprache auch immer von der Datenbank unterstützt wird. Objekt-Mapper sind oft langsamer, da sie Übersetzungscode verwenden, um zwischen Objekten und dem Datenbankformat zu mappen, das möglicherweise nicht die effizientesten Datenbankabfragen verwendet (dies trifft besonders zu, wenn der Mapper verschiedene Datenbank-Backends unterstützt und größere Kompromisse hinsichtlich unterstützter Datenbankfunktionen eingehen muss).
Der Vorteil der Verwendung eines ORM/ODM ist, dass Programmierer in Begriffen von JavaScript-Objekten denken können, anstatt in Begriffe der Datenbank. Dies ist insbesondere dann nützlich, wenn Sie mit verschiedenen Datenbanken arbeiten müssen (auf derselben oder anderen Websites). Sie bietet auch einen offensichtlichen Ort zur Durchführung der Datenvalidierung.
Hinweis: Die Verwendung von ODM/ORMs führt oft zu geringeren Entwicklungs- und Wartungskosten! Es sei denn, Sie sind sehr vertraut mit der nativen Abfragesprache oder die Leistung ist von größter Bedeutung, sollten Sie in Betracht ziehen, einen ODM zu verwenden.
Welchen ORM/ODM sollte ich verwenden?
Es gibt viele ODM/ORM-Lösungen, die auf der npm Package Manager-Seite verfügbar sind (schauen Sie sich die odm und orm Tags für einen Ausschnitt an!).
Einige zum Zeitpunkt des Schreibens populäre Lösungen sind:
- Mongoose: Mongoose ist ein MongoDB Objektmodellierungstool, das in einer asynchronen Umgebung arbeiten soll.
- Waterline: Ein ORM, das aus dem Express-basierten Sails Web-Framework extrahiert wurde. Es bietet eine einheitliche API zum Zugriff auf zahlreiche verschiedene Datenbanken, einschließlich Redis, MySQL, LDAP, MongoDB und Postgres.
- Bookshelf: Bietet sowohl versprechenbasierte als auch traditionelle Callback-Schnittstellen, Transaktionsunterstützung, vorsorgliches/verschachteltes Laden von Relationen, polymorphe Assoziationen und Unterstützung für Eins-zu-Eins-, Eins-zu-Viele- und Viele-zu-Viele-Relationen. Arbeitet mit PostgreSQL, MySQL und SQLite3.
- Objection: Macht es so einfach wie möglich, die volle Leistungsfähigkeit von SQL und der zugrunde liegenden Datenbank-Engine zu nutzen (unterstützt SQLite3, Postgres und MySQL).
- Sequelize ist ein auf Promises basierender ORM für Node.js und io.js. Er unterstützt die Dialekte PostgreSQL, MySQL, MariaDB, SQLite und MSSQL und verfügt über solide Transaktionsunterstützung, Relationen, Lese-Replikation und mehr.
- Node ORM2 ist ein Object Relationship Manager für NodeJS. Er unterstützt MySQL, SQLite und Postgres und hilft, mit der Datenbank im objektorientierten Ansatz zu arbeiten.
- GraphQL: Primär eine Abfragesprache für RESTful APIs, GraphQL ist sehr beliebt und bietet Funktionen zum Lesen von Daten aus Datenbanken.
Als allgemeine Regel sollten Sie sowohl die bereitgestellten Funktionen als auch die "Community-Aktivität" (Downloads, Beiträge, Fehlerberichte, Dokumentationsqualität usw.) bei der Auswahl einer Lösung berücksichtigen. Zum Zeitpunkt des Schreibens ist Mongoose bei weitem der beliebteste ODM und eine vernünftige Wahl, wenn Sie MongoDB für Ihre Datenbank verwenden.
Verwendung von Mongoose und MongoDB für die LocalLibrary
Für das Local Library Beispiel (und den Rest dieses Themas) werden wir den Mongoose ODM verwenden, um auf unsere Bibliotheksdaten zuzugreifen. Mongoose fungiert als Frontend zu MongoDB, einer Open-Source-NoSQL-Datenbank, die ein dokumentorientiertes Datenmodell verwendet. Eine "Sammlung" von "Dokumenten" in einer MongoDB-Datenbank ist analog zu einem "Tisch" von "Reihen" in einer relationalen Datenbank.
Diese Kombi aus ODM und Datenbank ist in der Node-Community extrem beliebt, zum Teil, weil der Dokumentenspeicher und das Abfragesystem sehr nach JSON aussieht und JavaScript-Entwicklern daher vertraut ist.
Hinweis: Sie müssen MongoDB nicht kennen, um Mongoose zu verwenden, obwohl Teile der Mongoose-Dokumentation _leichter zu verwenden und zu verstehen sind, wenn Sie bereits mit MongoDB vertraut sind.
Der Rest dieses Tutorials zeigt, wie man das Mongoose-Schema und die Modelle für das LocalLibrary Website Beispiel definiert und darauf zugreift.
Entwerfen der LocalLibrary-Modelle
Bevor Sie beginnen, die Modelle zu codieren, lohnt es sich, einige Minuten darüber nachzudenken, welche Daten wir speichern müssen und welche Beziehungen zwischen den verschiedenen Objekten bestehen.
Wir wissen, dass wir Informationen über Bücher (Titel, Zusammenfassung, Autor, Genre, ISBN) speichern müssen und dass wir mehrere Exemplare haben könnten (mit global eindeutigen IDs, Verfügbarkeitsstatus usw.). Möglicherweise müssen wir mehr Informationen über den Autor speichern als nur seinen Namen, und es könnte mehrere Autoren mit demselben oder ähnlichem Namen geben. Wir möchten Informationen basierend auf dem Buchtitel, Autor, Genre und Kategorie sortieren können.
Beim Entwurf Ihrer Modelle macht es Sinn, separate Modelle für jedes "Objekt" (eine Gruppe verwandter Informationen) zu haben. In diesem Fall sind einige offensichtliche Kandidaten für diese Modelle Bücher, Buchinstanzen und Autoren.
Sie könnten auch Modelle verwenden, um Auswahloptionen darzustellen (z.B. wie eine Dropdown-Liste von Auswahlmöglichkeiten), anstatt die Entscheidungen direkt in der Website zu kodieren — dies wird empfohlen, wenn nicht alle Optionen im Voraus bekannt sind oder geändert werden können. Ein gutes Beispiel ist ein Genre (z.B. Fantasy, Science-Fiction usw.).
Sobald wir uns für unsere Modelle und Felder entschieden haben, müssen wir über die Beziehungen zwischen ihnen nachdenken.
Vor diesem Hintergrund zeigt das folgende UML-Assoziationsdiagramm die Modelle, die wir in diesem Fall definieren werden (als Kästchen). Wie oben besprochen, haben wir Modelle für das Buch (die allgemeinen Details des Buches), die Buchinstanz (Status spezifischer physischer Kopien des Buches, die im System verfügbar sind) und den Autor erstellt. Wir haben uns auch entschieden, ein Modell für das Genre zu haben, damit die Werte dynamisch erstellt werden können. Wir haben uns entschieden, kein Modell für den BookInstance:status zu haben — wir werden die akzeptablen Werte hart kodieren, da wir nicht erwarten, dass diese sich ändern. Innerhalb von jedem der Kästchen können Sie den Modellnamen, die Feldnamen und -typen sowie die Methoden und deren Rückgabetypen sehen.
Das Diagramm zeigt auch die Beziehungen zwischen den Modellen, einschließlich ihrer Multiplizitäten. Die Multiplizitäten sind die Zahlen auf dem Diagramm, die die Anzahl (maximal und minimal) jeder im Verhältnis vorhandene Modell zeigen. Zum Beispiel zeigt die Verbindungslinie zwischen den Kästchen, dass Book und ein Genre miteinander verbunden sind. Die Zahlen nahe dem Book-Modell zeigen, dass ein Genre null oder mehr Books haben muss (so viele wie Sie möchten), während die Zahlen am anderen Ende der Linie neben dem Genre zeigen, dass ein Buch null oder mehr verbundene Genres haben kann.
Hinweis:
Wie in unserem Mongoose Primer unten diskutiert, ist es oft besser, das Feld, das die Beziehung zwischen den Dokumenten/Modellen definiert, in nur einem Modell zu haben (Sie können die umgekehrte Beziehung immer noch durch Suchen nach dem zugehörigen _id im anderen Modell finden). Unten haben wir uns entschieden, die Beziehung zwischen Book/Genre und Book/Author im Buchschema zu definieren und die Beziehung zwischen dem Book/BookInstance im BookInstance-Schema. Diese Wahl war etwas willkürlich — wir hätten das Feld ebenso gut im anderen Schema haben können.

Hinweis: Der nächste Abschnitt bietet eine grundlegende Einführung, wie Modelle definiert und verwendet werden. Während Sie es lesen, überlegen Sie, wie wir jedes der Modelle im obigen Diagramm konstruieren werden.
Datenbank-APIs sind asynchron
Datenbankmethoden zum Erstellen, Finden, Aktualisieren oder Löschen von Aufzeichnungen sind asynchron. Das bedeutet, dass die Methoden sofort zurückkehren und der Code, um den Erfolg oder das Scheitern der Methode zu behandeln, zu einem späteren Zeitpunkt läuft, wenn die Operation abgeschlossen ist. Anderer Code kann ausgeführt werden, während der Server auf den Abschluss der Datenbankoperation wartet, sodass der Server auf andere Anfragen reagieren kann.
JavaScript verfügt über eine Reihe von Mechanismen zur Unterstützung von asynchronem Verhalten. Früher verließ sich JavaScript stark auf das Übergeben von Callback-Funktionen an asynchrone Methoden, um die Erfolgs- und Fehlerfälle zu behandeln. In modernem JavaScript wurden Callbacks weitgehend durch Promises ersetzt. Promises sind Objekte, die von einer asynchronen Methode (sofort) zurückgegeben werden, die ihren zukünftigen Zustand repräsentieren. Wenn die Operation abgeschlossen ist, wird das Promise-Objekt "erledigt" und löst ein Objekt, das das Ergebnis der Operation oder einen Fehler darstellt.
Es gibt zwei Hauptarten, wie Sie Promises verwenden können, um Code auszuführen, wenn ein Promise erledigt ist, und wir empfehlen Ihnen dringend, Wie man Promises verwendet zu lesen, um einen Überblick über beide Ansätze zu erhalten.
In diesem Tutorial werden wir hauptsächlich await verwenden, um auf den Abschluss eines Promises innerhalb einer async function zu warten, da dies zu besser lesbarem und verständlicherem asynchronem Code führt.
Bei diesem Ansatz markieren Sie eine Funktion mit dem Schlüsselwort async function als asynchron und verwenden dann innerhalb dieser Funktion await auf jede Methode, die ein Promise zurückgibt.
Wenn die asynchrone Funktion ausgeführt wird, wird ihre Operation an der ersten await-Methode pausiert, bis das Promise erfüllt wird.
Aus der Perspektive des umgebenden Codes wird die asynchrone Funktion dann zurückgegeben und der Code danach kann ausgeführt werden.
Später, wenn das Promise abgeschlossen ist, gibt die await-Methode innerhalb der asynchronen Funktion mit dem Ergebnis zurück, oder es wird ein Fehler ausgelöst, wenn das Promise zurückgewiesen wurde.
Der Code in der asynchronen Funktion wird dann ausgeführt, bis entweder eine weitere await-Methode auftritt, an welchem Punkt er erneut pausiert, oder bis der gesamte Code der Funktion ausgeführt wurde.
Das folgende Beispiel zeigt, wie dies funktioniert.
myFunction() ist eine asynchrone Funktion, die innerhalb eines try...catch Blocks aufgerufen wird.
Wenn myFunction() ausgeführt wird, wird die Codeausführung an der Stelle methodThatReturnsPromise() pausiert, bis das Promise erfüllt wird, dann wird der Code zu aFunctionThatReturnsPromise() fortgesetzt und wartet wieder.
Der Code im catch-Block wird ausgeführt, wenn ein Fehler in der asynchronen Funktion ausgelöst wird, was passiert, wenn das Promise, das von einer der Methoden zurückgegeben wird, abgelehnt wird.
async function myFunction {
// ...
await someObject.methodThatReturnsPromise();
// ...
await aFunctionThatReturnsPromise();
// ...
}
try {
// ...
myFunction();
// ...
} catch (e) {
// error handling code
}
Die asynchronen Methoden oben werden in der Reihenfolge ausgeführt.
Wenn die Methoden nicht voneinander abhängen, können Sie sie parallel ausführen und die gesamte Operation schneller abschließen.
Dies wird mit der Promise.all()-Methode durchgeführt, die ein Iterable von Promises als Eingabe akzeptiert und ein einzelnes Promise zurückgibt.
Dieses zurückgegebene Promise wird erfüllt, wenn alle Promises der Eingabe erfüllt sind, mit einem Array der Erfüllungswerte.
Es wird abgelehnt, wenn eines der Eingabe-Promises abgelehnt wird, mit diesem ersten Ablehnungsgrund.
Der Code unten zeigt, wie das funktioniert.
Zuerst haben wir zwei Funktionen, die Promises zurückgeben.
Wir await auf beide, um abzuschließen, indem wir das Promise verwenden, das von Promise.all() zurückgegeben wird.
Sobald beide abgeschlossen sind, gibt await zurück und das Array der Ergebnisse wird gefüllt,
die Funktion fährt dann mit der nächsten await fort und wartet, bis das von anotherFunctionThatReturnsPromise() zurückgegebene Promise abgeschlossen ist.
Sie würden die myFunction() in einem try...catch Block aufrufen, um Fehler abzufangen.
async function myFunction {
// ...
const [resultFunction1, resultFunction2] = await Promise.all([
functionThatReturnsPromise1(),
functionThatReturnsPromise2()
]);
// ...
await anotherFunctionThatReturnsPromise(resultFunction1);
}
Promises mit await/async ermöglichen sowohl flexible als auch "verständliche" Kontrolle über die asynchrone Ausführung!
Mongoose-Primer
Dieser Abschnitt bietet einen Überblick darüber, wie man Mongoose mit einer MongoDB-Datenbank verbindet, wie man ein Schema und ein Modell definiert und wie man grundlegende Abfragen macht.
Hinweis: Dieser Primer ist stark durch den Mongoose-Schnellstart auf npm und die offizielle Dokumentation beeinflusst.
Installation von Mongoose und MongoDB
Mongoose wird in Ihrem Projekt (package.json) wie jede andere Abhängigkeit installiert — mit npm. Um es zu installieren, verwenden Sie den folgenden Befehl im Projektordner:
npm install mongoose
Die Installation von Mongoose fügt alle seine Abhängigkeiten hinzu, einschließlich des MongoDB-Datenbanktreibers, installiert jedoch nicht MongoDB selbst. Wenn Sie einen MongoDB-Server installieren möchten, können Sie hier Installationsprogramme herunterladen für verschiedene Betriebssysteme und es lokal installieren. Sie können auch cloudbasierte MongoDB-Instanzen verwenden.
Hinweis: Für dieses Tutorial verwenden wir den MongoDB Atlas cloudbasierten Datenbank als Dienst Free-Tier, um die Datenbank bereitzustellen. Diese ist für die Entwicklung geeignet und sinnvoll für das Tutorial, da sie die "Installation" betriebssystemunabhängig macht (Datenbank als Dienst ist auch ein Ansatz, den Sie für Ihre Produktionsdatenbank verwenden könnten).
Verbindung zu MongoDB
Mongoose erfordert eine Verbindung zu einer MongoDB-Datenbank.
Sie können require() aufrufen und eine Verbindung zu einer lokal gehosteten Datenbank mit mongoose.connect() herstellen, wie unten gezeigt (für das Tutorial verbinden wir uns stattdessen mit einer internetgehosteten Datenbank).
// Import the mongoose module
const mongoose = require("mongoose");
// Set `strictQuery: false` to globally opt into filtering by properties that aren't in the schema
// Included because it removes preparatory warnings for Mongoose 7.
// See: https://mongoosejs.com/docs/migrating_to_6.html#strictquery-is-removed-and-replaced-by-strict
mongoose.set("strictQuery", false);
// Define the database URL to connect to.
const mongoDB = "mongodb://127.0.0.1/my_database";
// Wait for database to connect, logging an error if there is a problem
main().catch((err) => console.log(err));
async function main() {
await mongoose.connect(mongoDB);
}
Hinweis:
Wie im Abschnitt Datenbank-APIs sind asynchron besprochen, haben wir hier await für das von der connect() Methode zurückgegebene Promise innerhalb einer async-Funktion verwendet.
Wir verwenden den Promise catch()-Handler, um Fehler beim Verbindungsversuch zu behandeln, aber wir hätten auch main() innerhalb eines try...catch Blocks aufrufen können.
Sie können das Standard-Connection-Objekt mit mongoose.connection erhalten.
Wenn Sie zusätzliche Verbindungen erstellen müssen, können Sie mongoose.createConnection() verwenden.
Dies nimmt denselben Typ von Datenbank-URI (mit Host, Datenbank, Port, Optionen usw.) wie connect() und gibt ein Connection-Objekt zurück).
Beachten Sie, dass createConnection() sofort zurückkehrt; wenn Sie darauf warten müssen, dass die Verbindung hergestellt wird, können Sie diese mit asPromise() für ein Promise aufrufen (mongoose.createConnection(mongoDB).asPromise()).
Definieren und Erstellen von Modellen
Modelle werden mit der Schema-Schnittstelle definiert. Das Schema ermöglicht es Ihnen, die in jedem Dokument gespeicherten Felder zusammen mit deren Validierungsanforderungen und Standardwerten zu definieren. Außerdem können Sie statische und Instanz-Helfermethoden definieren, die es einfacher machen, mit Ihren Datentypen zu arbeiten, und auch virtuelle Eigenschaften, die Sie wie jedes andere Feld verwenden können, die aber nicht wirklich in der Datenbank gespeichert werden (wir werden dies weiter unten im Detail erläutern).
Schemas werden dann mit der mongoose.model()-Methode in Modelle "kompiliert". Sobald Sie ein Modell haben, können Sie es verwenden, um Objekte des angegebenen Typs zu finden, zu erstellen, zu aktualisieren und zu löschen.
Hinweis:
Jedes Modell wird einer Sammlung von Dokumenten in der MongoDB-Datenbank zugeordnet. Die Dokumente enthalten die im Modell Schema definierten Felder/Schemata-Typen.
Definieren von Schemas
Der unten gezeigte Codeausschnitt zeigt, wie Sie ein einfaches Schema definieren können. Zuerst require() Sie Mongoose und dann verwenden Sie den Schema-Konstruktor, um eine neue Schema-Instanz zu erstellen, indem Sie die verschiedenen Felder im Objektparameter des Konstruktors definieren.
// Require Mongoose
const mongoose = require("mongoose");
// Define a schema
const Schema = mongoose.Schema;
const SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
Im oben gezeigten Fall haben wir nur zwei Felder, einen String und ein Datum. In den nächsten Abschnitten zeigen wir einige der anderen Feldtypen, die Validierung und andere Methoden.
Erstellen eines Modells
Modelle werden mit der mongoose.model()-Methode aus Schemas erstellt:
// Define schema
const Schema = mongoose.Schema;
const SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
// Compile model from schema
const SomeModel = mongoose.model("SomeModel", SomeModelSchema);
Das erste Argument ist der singuläre Name der Sammlung, die für Ihr Modell erstellt wird (Mongoose erstellt die Datenbanksammlung für das Modell SomeModel oben), und das zweite Argument ist das Schema, das Sie bei der Erstellung des Modells verwenden möchten.
Hinweis: Sobald Sie Ihre Modellklassen definiert haben, können Sie sie verwenden, um Datensätze zu erstellen, zu aktualisieren oder zu löschen und Abfragen durchzuführen, um alle Datensätze oder bestimmte Untergruppen von Datensätzen zu erhalten. Wir zeigen Ihnen, wie Sie dies im Abschnitt Verwendung von Modellen tun und wenn wir unsere Ansichten erstellen.
Schema-Typen (Felder)
Ein Schema kann eine beliebige Anzahl von Feldern haben — jedes repräsentiert ein Feld in den in MongoDB gespeicherten Dokumenten. Ein Beispielschema, das viele der gängigen Feldtypen zeigt und wie sie deklariert werden, ist unten gezeigt.
const schema = new Schema({
name: String,
binary: Buffer,
living: Boolean,
updated: { type: Date, default: Date.now() },
age: { type: Number, min: 18, max: 65, required: true },
mixed: Schema.Types.Mixed,
_someId: Schema.Types.ObjectId,
array: [],
ofString: [String], // You can also have an array of each of the other types too.
nested: { stuff: { type: String, lowercase: true, trim: true } },
});
Die meisten der SchemaTypes (die Deskriptoren nach "type:" oder nach Feldnamen) sind selbsterklärend. Die Ausnahmen sind:
ObjectId: Repräsentiert spezifische Instanzen eines Modells in der Datenbank. Zum Beispiel könnte ein Buch dies verwenden, um sein Autorenobjekt zu repräsentieren. Dies wird tatsächlich die eindeutige ID (_id) für das angegebene Objekt enthalten. Wir können diepopulate()Methode verwenden, um die zugehörigen Informationen bei Bedarf abzurufen.Mixed: Ein beliebiger Schema-Typ.[]: Ein Array von Elementen. Sie können JavaScript-Array-Operationen auf diesen Modellen durchführen (push, pop, unshift usw.). Die Beispiele oben zeigen ein Array von Objekten ohne angegebenen Typ und ein Array vonString-Objekten, aber Sie können ein Array von jedem Objekttyp haben.
Der Code zeigt auch beide Möglichkeiten, ein Feld zu deklarieren:
-
Feld Name und Typ als Schlüssel-Wert-Paar (d.h. wie bei den Feldern
name,binaryundliving). -
Feld Name, gefolgt von einem Objekt, das den
typeund alle anderen Optionen für das Feld definiert. Optionen umfassen Dinge wie:- Standardwerte.
- Eingebaute Validatoren (z.B. Maximal-/Minimalwerte) und benutzerdefinierte Validierungsfunktionen.
- Ob das Feld erforderlich ist
- Ob
String-Felder automatisch in Kleinbuchstaben, Großbuchstaben oder getrimmt werden sollen (z.B.{ type: String, lowercase: true, trim: true })
Für weitere Informationen über Optionen siehe SchemaTypes (Mongoose-Dokumentation).
Validierung
Mongoose bietet eingebaute und benutzerdefinierte Validatoren sowie synchrone und asynchrone Validatoren. Es ermöglicht Ihnen, sowohl den akzeptablen Wertebereich als auch die Fehlermeldung für Validierungsfehler in allen Fällen anzugeben.
Zu den eingebauten Validatoren gehören:
- Alle SchemaTypes haben den eingebauten required Validator. Dies wird verwendet, um anzugeben, ob das Feld bereitgestellt werden muss, um ein Dokument zu speichern.
- Numbers haben min und max Validatoren.
- Strings haben:
Das unten leicht abgewandelte Beispiel zeigt, wie Sie einige der Validatortypen und Fehlermeldungen angeben können:
const breakfastSchema = new Schema({
eggs: {
type: Number,
min: [6, "Too few eggs"],
max: 12,
required: [true, "Why no eggs?"],
},
drink: {
type: String,
enum: ["Coffee", "Tea", "Water"],
},
});
Für vollständige Informationen zur Feldvalidierung siehe Validation (Mongoose-Dokumentation).
Virtuelle Eigenschaften
Virtuelle Eigenschaften sind Dokumenteigenschaften, die Sie abrufen und festlegen können, die jedoch nicht in MongoDB gespeichert werden. Getter sind nützlich zum Formatieren oder Kombinieren von Feldern, während Setter nützlich sind, um einen einzelnen Wert in mehrere Werte zur Speicherung zu zerlegen. Das Beispiel in der Dokumentation konstruieren (und zerlegen) eine vollständige Nameneigenschaft aus einem Vor- und Nachnamenfeld, was einfacher und sauberer ist als das Erstellen eines vollständigen Namens jedes Mal, wenn er in einer Vorlage verwendet wird.
Hinweis:
Wir verwenden eine virtuelle Eigenschaft in der Bibliothek, um eine eindeutige URL für jeden Modeldatensatz mithilfe eines Pfads und des _id-Werts des Datensatzes zu definieren.
Für weitere Informationen siehe Virtuals (Mongoose-Dokumentation).
Methoden und Abfrage-Helfer
Ein Schema kann auch Instanzmethoden, statische Methoden und Abfrage-Helfer haben. Die Instanz- und statischen Methoden sind ähnlich, mit dem offensichtlichen Unterschied, dass eine Instanzmethode mit einem bestimmten Datensatz verbunden ist und Zugriff auf das aktuelle Objekt hat. Abfrage-Helfer ermöglichen es Ihnen, die kettbare Abfrage-API von Mongoose zu erweitern (z.B. können Sie eine Abfrage "byName" hinzufügen, zusätzlich zu den find(), findOne() und findById()-Methoden).
Verwendung von Modellen
Sobald Sie ein Schema erstellt haben, können Sie es verwenden, um Modelle zu erstellen. Das Modell repräsentiert eine Sammlung von Dokumenten in der Datenbank, die Sie durchsuchen können, während die Instanzen des Modells einzelne Dokumente darstellen, die Sie speichern und abrufen können.
Wir bieten unten eine kurze Übersicht. Für weitere Informationen siehe: Models (Mongoose-Dokumentation).
Hinweis:
Erstellung, Aktualisierung, Löschung und Abfrage von Datensätzen sind asynchrone Operationen, die ein Promise zurückgeben.
Die unten gezeigten Beispiele zeigen nur die Nutzung der relevanten Methoden und await (d.h. der wesentliche Code zur Nutzung der Methoden).
Die umgebende async function und der try...catch Block, um Fehler abzufangen, werden der Klarheit halber weggelassen.
Für weitere Informationen zur Verwendung von await/async siehe Datenbank-APIs sind asynchron weiter oben.
Erstellen und Ändern von Dokumenten
Um einen Datensatz zu erstellen, können Sie eine Instanz des Modells definieren und dann save() darauf aufrufen.
In den unten gezeigten Beispielen nehmen wir an, dass SomeModel ein Modell (mit einem einzigen Feld name) ist, das wir aus unserem Schema erstellt haben.
// Create an instance of model SomeModel
const awesome_instance = new SomeModel({ name: "awesome" });
// Save the new model instance asynchronously
await awesome_instance.save();
Sie können auch create() verwenden, um die Modellinstanz gleichzeitig zu definieren und zu speichern.
Unten erstellen wir nur eine, aber Sie können mehrere Instanzen erstellen, indem Sie ein Array von Objekten übergeben.
await SomeModel.create({ name: "also_awesome" });
Jedes Modell hat eine zugehörige Verbindung (das wird die Standardverbindung sein, wenn Sie mongoose.model() verwenden). Sie erstellen eine neue Verbindung und rufen .model() darauf auf, um die Dokumente in einer anderen Datenbank zu erstellen.
Sie können auf die Felder in diesem neuen Datensatz mit der Punkt-Syntax zugreifen und die Werte ändern. Sie müssen save() oder update() aufrufen, um geänderte Werte in der Datenbank zu speichern.
// Access model field values using dot notation
console.log(awesome_instance.name); //should log 'also_awesome'
// Change record by modifying the fields, then calling save().
awesome_instance.name = "New cool name";
await awesome_instance.save();
Suchen nach Datensätzen
Sie können mit Abfragemethoden nach Datensätzen suchen, indem Sie die Abfragebedingungen als JSON-Dokument angeben. Der unten gezeigte Codeausschnitt zeigt, wie Sie alle Athleten in einer Datenbank finden könnten, die Tennis spielen, und zeigt nur die Felder für den Namen und das Alter des Athleten an. Hier geben wir nur ein übereinstimmendes Feld (Sportart) an, aber Sie können weitere Kriterien hinzufügen, reguläre Ausdruckskriterien angeben oder die Bedingungen ganz entfernen, um alle Athleten zurückzugeben.
const Athlete = mongoose.model("Athlete", yourSchema);
// find all athletes who play tennis, returning the 'name' and 'age' fields
const tennisPlayers = await Athlete.find(
{ sport: "Tennis" },
"name age",
).exec();
Hinweis: Es ist wichtig, sich daran zu erinnern, dass das Nichtfinden eines Ergebnisses kein Fehler einer Suche ist — aber es kann ein fehlgeschlagener Fall im Kontext Ihrer Anwendung sein. Wenn Ihre Anwendung erwartet, dass eine Suche einen Wert findet, können Sie die Anzahl der in dem Ergebnis zurückgegebenen Einträge überprüfen.
Abfrage-APIs, wie find(), geben eine Variable vom Typ Query zurück.
Sie können ein Abfrageobjekt verwenden, um eine Abfrage in Teilen aufzubauen, bevor Sie sie mit der exec() Methode ausführen.
exec() führt die Abfrage aus und gibt ein Promise zurück, auf das Sie für das Ergebnis await anwenden können.
// find all athletes that play tennis
const query = Athlete.find({ sport: "Tennis" });
// selecting the 'name' and 'age' fields
query.select("name age");
// limit our results to 5 items
query.limit(5);
// sort by age
query.sort({ age: -1 });
// execute the query at a later time
query.exec();
Oben haben wir die Abfragebedingungen in der find() Methode definiert. Wir können dies auch mit einer where() Funktion tun und alle Teile unserer Abfrage mit dem Punktoperator (.) verketten, anstatt sie separat hinzuzufügen.
Der unten gezeigte Codeausschnitt ist derselbe wie unsere obige Abfrage, mit einer zusätzlichen Bedingung für das Alter.
Athlete.find()
.where("sport")
.equals("Tennis")
.where("age")
.gt(17)
.lt(50) // Additional where query
.limit(5)
.sort({ age: -1 })
.select("name age")
.exec();
Die find() Methode ruft alle übereinstimmenden Datensätze ab. Oft möchten Sie jedoch nur einen Treffer abfragen. Die folgenden Methoden fragen nach einem einzelnen Datensatz:
findById(): Findet das Dokument mit dem angegebenenid(jedes Dokument hat eine eindeutigeid).findOne(): Findet ein einzelnes Dokument, das die angegebenen Kriterien erfüllt.findByIdAndDelete(),findByIdAndUpdate(),findOneAndRemove(),findOneAndUpdate(): Findet ein einzelnes Dokument nachidoder Kriterien und aktualisiert oder entfernt es entweder. Dies sind nützliche Komfortfunktionen zum Aktualisieren und Entfernen von Datensätzen.
Hinweis:
Es gibt auch eine countDocuments() Methode, mit der Sie die Anzahl der Elemente erhalten können, die den Bedingungen entsprechen. Dies ist nützlich, wenn Sie eine Zählung ohne tatsächliches Abrufen der Datensätze durchführen möchten.
Es gibt noch viel mehr, was Sie mit Abfragen tun können. Für weitere Informationen siehe: Queries (Mongoose-Dokumentation).
Arbeiten mit verwandten Dokumenten — Population
Sie können Referenzen von einem Dokument/Modellinstanz zu einer anderen erstellen, indem Sie das ObjectId Schema-Feld verwenden, oder von einem Dokument zu vielen, indem Sie ein Array von ObjectIds verwenden. Das Feld speichert die ID des zugehörigen Modells. Wenn Sie den tatsächlichen Inhalt des zugehörigen Dokuments benötigen, können Sie die populate() Methode in einer Abfrage verwenden, um die ID durch die tatsächlichen Daten zu ersetzen.
Zum Beispiel definiert das folgende Schema Autoren und Geschichten.
Jeder Autor kann mehrere Geschichten haben, die wir als ein Array von ObjectId darstellen.
Jede Geschichte kann einen einzigen Autor haben.
Die ref-Eigenschaft teilt dem Schema mit, welches Modell diesem Feld zugewiesen werden kann.
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const authorSchema = new Schema({
name: String,
stories: [{ type: Schema.Types.ObjectId, ref: "Story" }],
});
const storySchema = new Schema({
author: { type: Schema.Types.ObjectId, ref: "Author" },
title: String,
});
const Story = mongoose.model("Story", storySchema);
const Author = mongoose.model("Author", authorSchema);
Wir können unsere Referenzen zum verbundenen Dokument speichern, indem wir den _id Wert zuweisen.
Unten erstellen wir einen Autor, dann eine Geschichte und weisen die Autoren-ID unserem Autor-Feld der Geschichte zu.
const bob = new Author({ name: "Bob Smith" });
await bob.save();
// Bob now exists, so lets create a story
const story = new Story({
title: "Bob goes sledding",
author: bob._id, // assign the _id from our author Bob. This ID is created by default!
});
await story.save();
Hinweis:
Ein großer Vorteil dieses Programmierstils ist, dass wir den Hauptstrang unseres Codes nicht mit Fehlerprüfung komplizieren müssen.
Wenn eine der save()-Operationen fehlschlägt, lehnt das Promise ab und ein Fehler wird ausgelöst.
Unser Fehlerbehandlungscode behandelt das separat (normalerweise in einem catch() Block), so dass die Absicht unseres Codes sehr klar ist.
Unser Geschichtsdokument hat jetzt einen Autor, der durch die ID des Autor-Dokuments referenziert wird. Um die Autoreninformationen in den Geschichtsergebnissen zu erhalten, verwenden wir populate(), wie unten gezeigt.
Story.findOne({ title: "Bob goes sledding" })
.populate("author") // Replace the author id with actual author information in results
.exec();
Hinweis: Aufmerksame Leser haben vielleicht bemerkt, dass wir einen Autor zu unserer Geschichte hinzugefügt haben, aber nichts getan haben, um unsere Geschichte zu unserem Autoren-Array hinzuzufügen. Wie können wir dann alle Geschichten eines bestimmten Autors erhalten? Eine Möglichkeit wäre, unsere Geschichte dem Autoren-Array hinzuzufügen, aber dies würde dazu führen, dass wir zwei Stellen haben, an denen die Informationen über Beziehungen zwischen Autoren und Geschichten gepflegt werden müssen.
Eine bessere Möglichkeit ist, die _id unseres autors zu erhalten und dann find() zu verwenden, um nach dieser im Autorenfeld bei allen Geschichten zu suchen.
Story.find({ author: bob._id }).exec();
Das ist fast alles, was Sie über die Arbeit mit verwandten Elementen für dieses Tutorial wissen müssen. Für detailliertere Informationen siehe Population (Mongoose-Dokumentation).
Ein Schema/Modell pro Datei
Während Sie Schemas und Modelle mit jeder gewünschten Dateistruktur erstellen können, empfehlen wir dringend, jedes Modell-Schema in einem eigenen Modul (Datei) zu definieren und dann die Methode zum Erstellen des Modells zu exportieren. Dies wird unten gezeigt:
// File: ./models/some-model.js
// Require Mongoose
const mongoose = require("mongoose");
// Define a schema
const Schema = mongoose.Schema;
const SomeModelSchema = new Schema({
a_string: String,
a_date: Date,
});
// Export function to create "SomeModel" model class
module.exports = mongoose.model("SomeModel", SomeModelSchema);
Sie können dann das Modell sofort in anderen Dateien anfordern und verwenden. Unten zeigen wir, wie Sie es verwenden könnten, um alle Instanzen des Modells zu erhalten.
// Create a SomeModel model just by requiring the module
const SomeModel = require("../models/some-model");
// Use the SomeModel object (model) to find all SomeModel records
const modelInstances = await SomeModel.find().exec();
Einrichten der MongoDB-Datenbank
Jetzt, da wir etwas darüber gelernt haben, was Mongoose tun kann und wie wir unsere Modelle entwerfen möchten, ist es an der Zeit, mit der Arbeit an der LocalLibrary Website zu beginnen. Das erste, was wir tun wollen, ist eine MongoDB-Datenbank einzurichten, die wir zum Speichern unserer Bibliotheksdaten verwenden können.
Für dieses Tutorial verwenden wir die MongoDB Atlas cloudgehostete Sandbox-Datenbank. Diese Datenbankstufe wird nicht als geeignet für Produktionswebsites betrachtet, da sie keine Redundanz hat, aber sie ist großartig für Entwicklung und Prototyping. Wir verwenden sie hier, weil sie kostenlos und einfach einzurichten ist und weil MongoDB Atlas ein beliebter Datenbank als Dienst Anbieter ist, den Sie vernünftigerweise für Ihre Produktionsdatenbank wählen könnten (andere beliebte Optionen zum Zeitpunkt des Schreibens sind ScaleGrid und ObjectRocket).
Hinweis: Wenn Sie es vorziehen, können Sie eine lokale MongoDB-Datenbank einrichten, indem Sie die entsprechenden Binärdateien für Ihr System herunterladen und installieren. Die restlichen Anweisungen in diesem Artikel wären ähnlich, abgesehen von der Datenbank-URL, die Sie bei der Verbindung angeben würden. Im Tutorial Express Tutorial Teil 7: Implementierung in die Produktion hosten wir sowohl die Anwendung als auch die Datenbank auf Railway, aber wir könnten ebenso eine Datenbank auf MongoDB Atlas verwenden haben.
Zuerst müssen Sie ein Konto erstellen bei MongoDB Atlas (dies ist kostenlos und erfordert nur, dass Sie grundlegende Kontaktdaten eingeben und deren Nutzungsbedingungen zustimmen).
Nach der Anmeldung gelangen Sie auf den Startbildschirm.
-
Klicken Sie auf die Schaltfläche + Create im Abschnitt Overview.
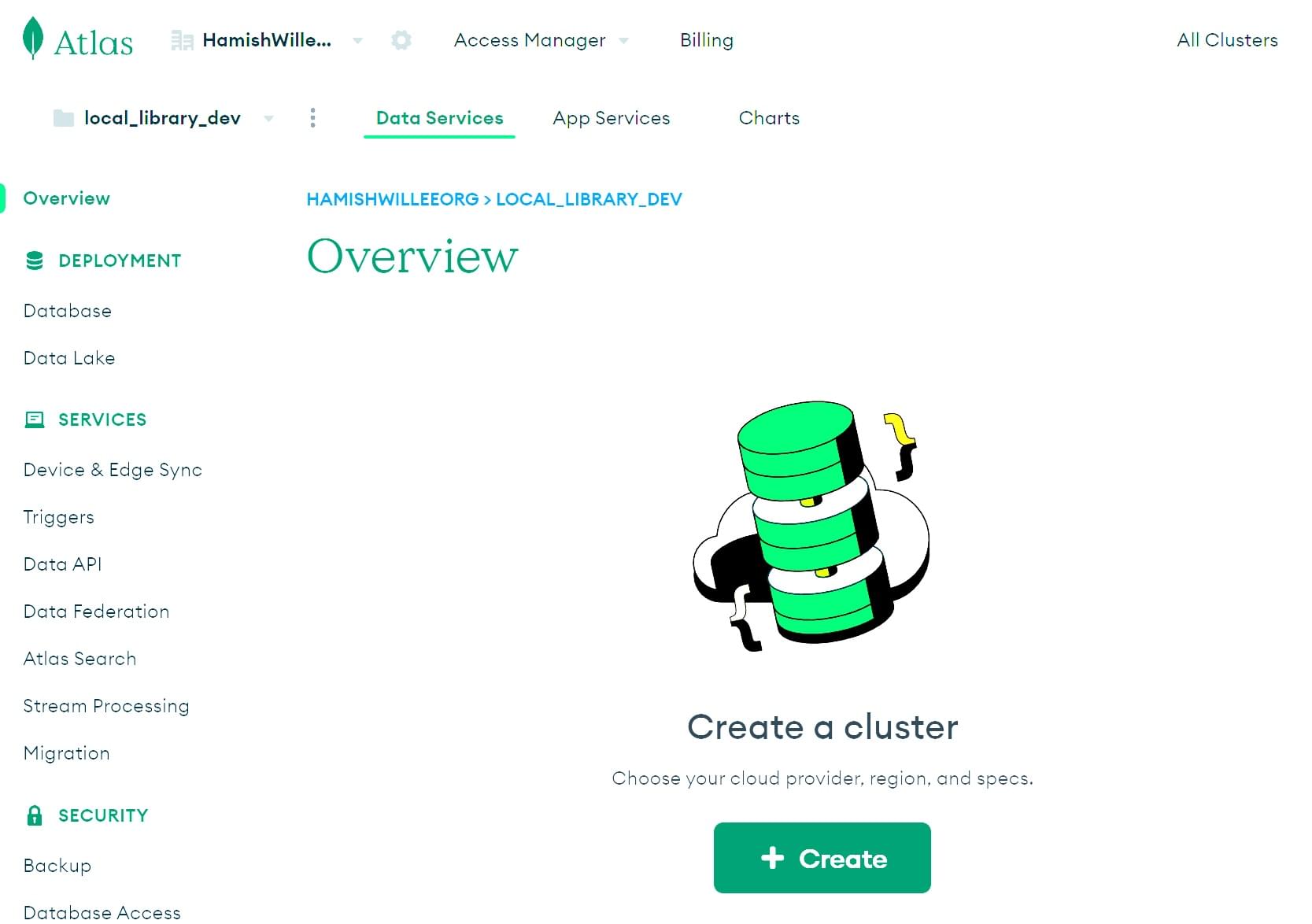
-
Dies öffnet den Bildschirm Deploy your cluster. Klicken Sie auf die Option Vorlage M0 FREE.
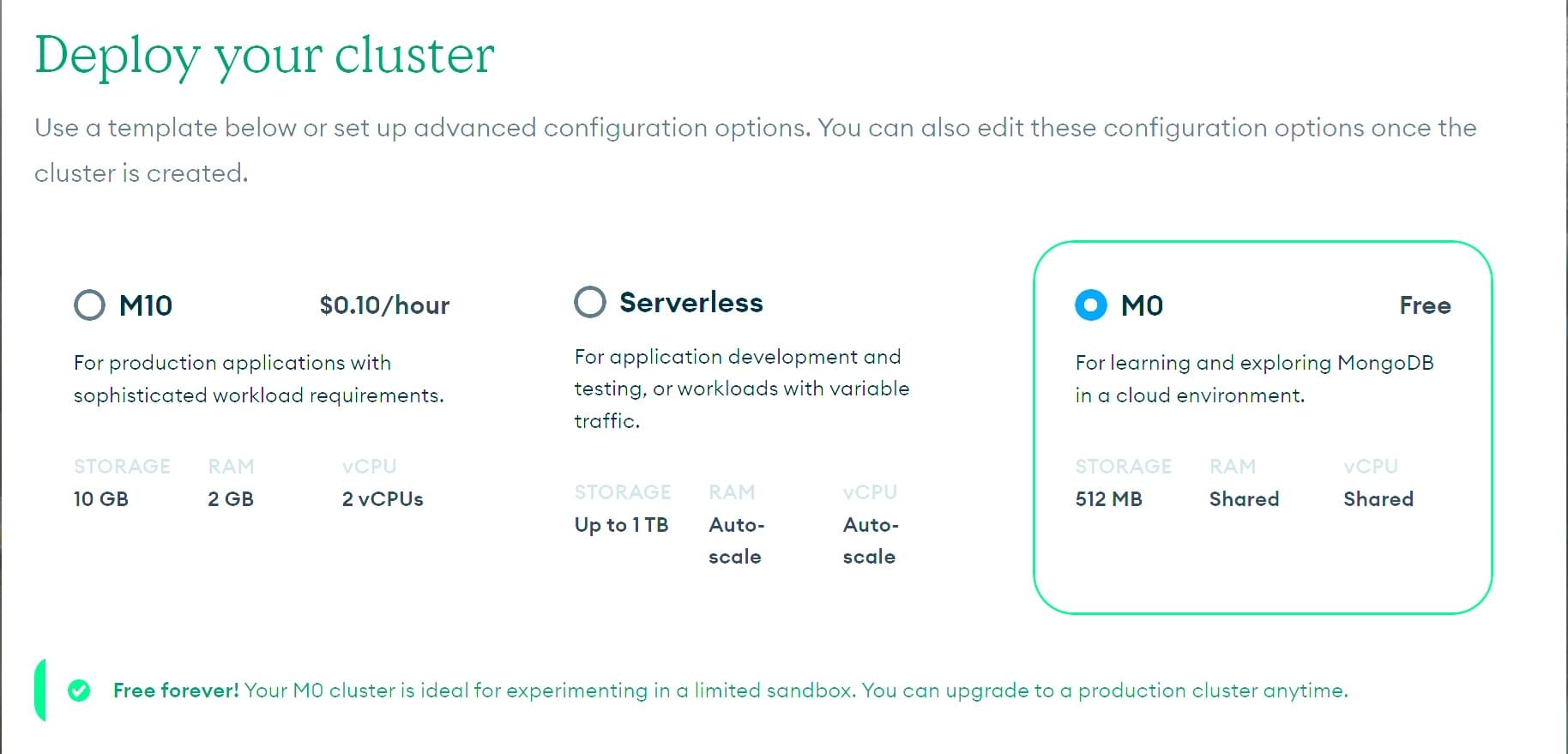
-
Scrollen Sie die Seite herunter, um die verschiedenen Optionen zu sehen, die Sie wählen können.
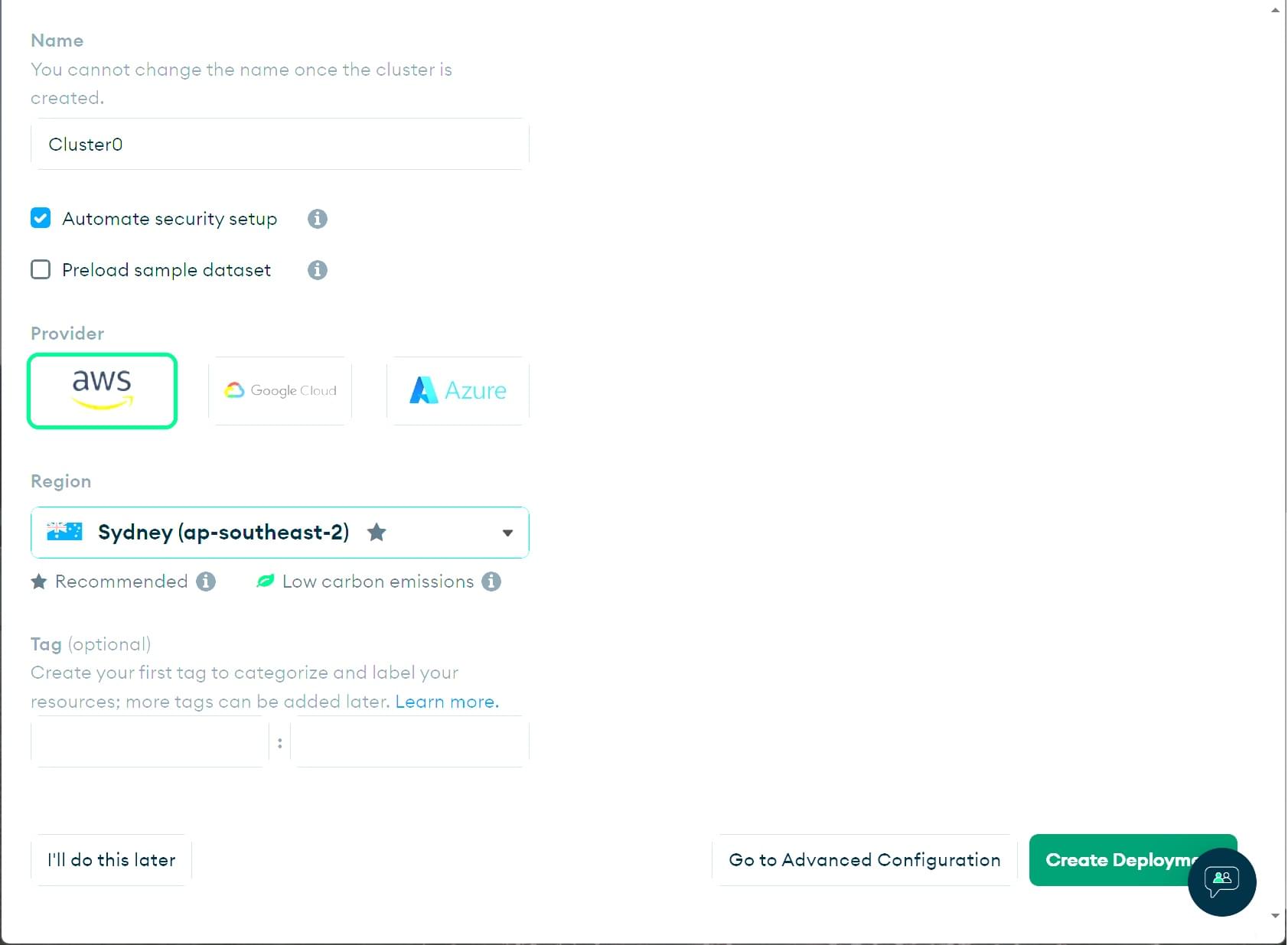
- Sie können den Namen Ihres Clusters unter Cluster Name ändern.
Wir belassen es bei
Cluster0für dieses Tutorial. - Deaktivieren Sie das Kontrollkästchen Preload sample dataset, da wir später unsere eigenen Beispieldaten importieren werden
- Wählen Sie einen beliebigen Anbieter und eine beliebige Region aus den Abschnitten Provider und Region. Verschiedene Regionen bieten unterschiedliche Anbieter.
- Tags sind optional. Wir werden sie hier nicht verwenden.
- Klicken Sie auf die Schaltfläche Create deployment (die Erstellung des Clusters dauert einige Minuten).
- Sie können den Namen Ihres Clusters unter Cluster Name ändern.
Wir belassen es bei
-
Dies öffnet den Abschnitt Security Quickstart.
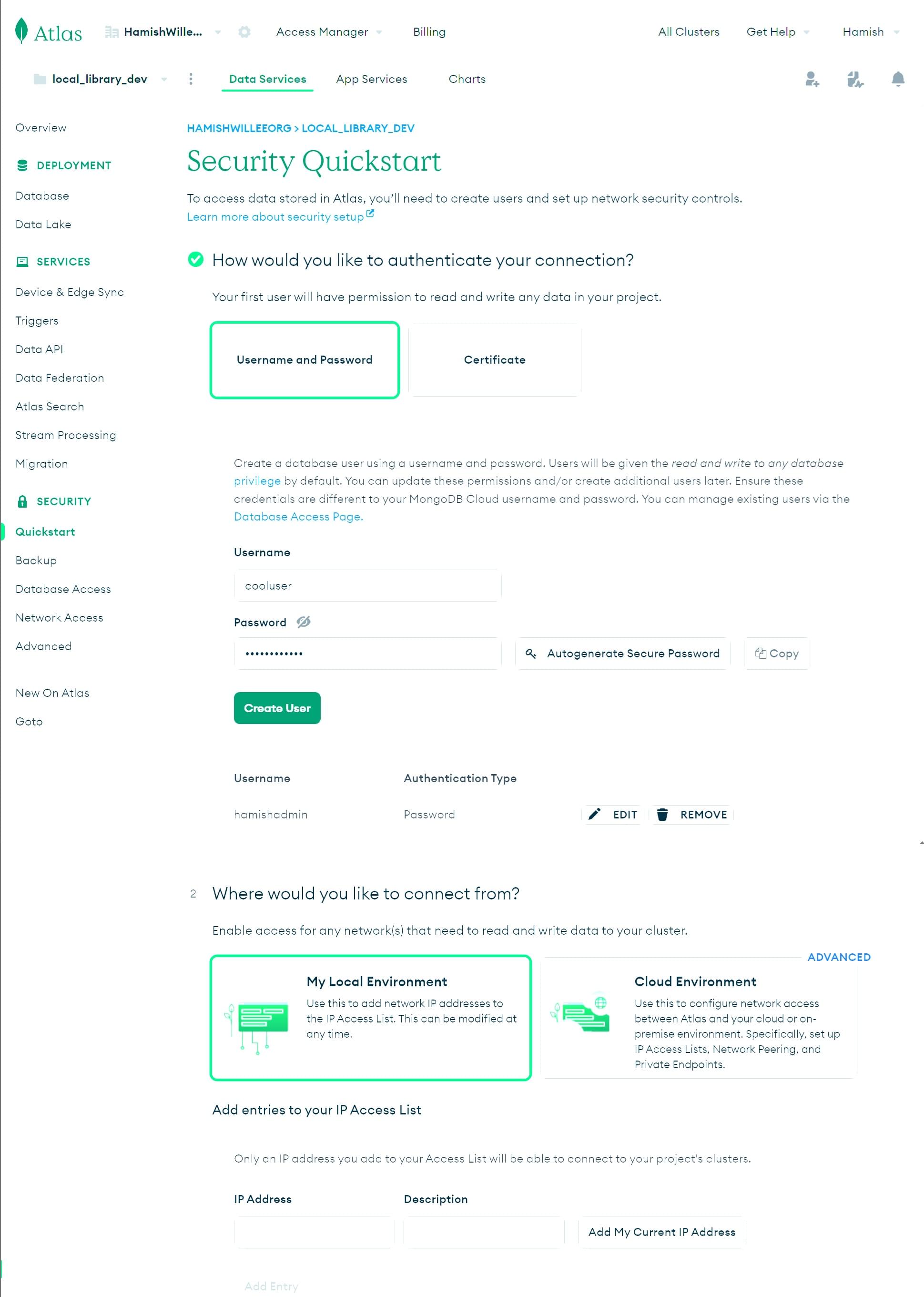
-
Geben Sie einen Benutzernamen und ein Passwort ein, damit Ihre Anwendung auf die Datenbank zugreifen kann (oben haben wir einen neuen Login "cooluser" erstellt). Denken Sie daran, die Anmeldeinformationen sicher zu speichern, da wir sie später benötigen werden. Klicken Sie auf die Schaltfläche Create User.
Hinweis: Vermeiden Sie die Verwendung von Sonderzeichen in Ihrem MongoDB-Benutzer-Passwort. Mongoose kann den Verbindungsstring möglicherweise nicht richtig parsen.
-
Wählen Sie Add by current IP address, um den Zugriff von Ihrem aktuellen Computer zu ermöglichen
-
Geben Sie
0.0.0.0/0in das IP-Adressenfeld ein und klicken Sie dann auf die Schaltfläche Add Entry. Dies teilt MongoDB mit, dass wir den Zugriff von überall her erlauben möchten.Hinweis: Es ist eine bewährte Praxis, die IP-Adressen einzuschränken, die auf Ihre Datenbank und andere Ressourcen zugreifen können. Hier erlauben wir eine Verbindung von überall her, weil wir nicht wissen, woher die Anforderung nach der Implementierung kommt.
-
Klicken Sie auf die Schaltfläche Finish and Close.
-
-
Dies öffnet den folgenden Bildschirm. Klicken Sie auf die Schaltfläche Go to Overview.
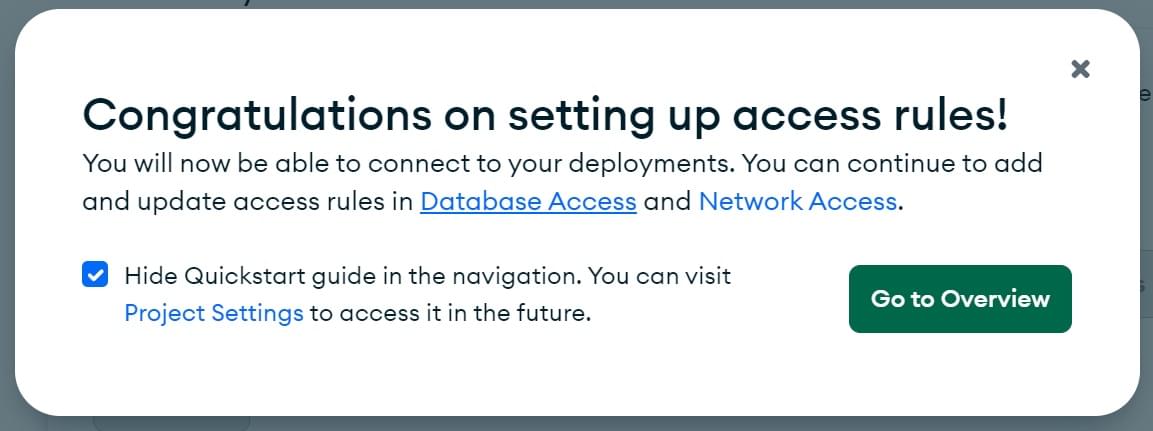
-
Sie kehren zum Bildschirm Overview zurück. Klicken Sie im Bereich Deployment im Menü links auf den Abschnitt Database. Klicken Sie auf die Schaltfläche Browse Collections.
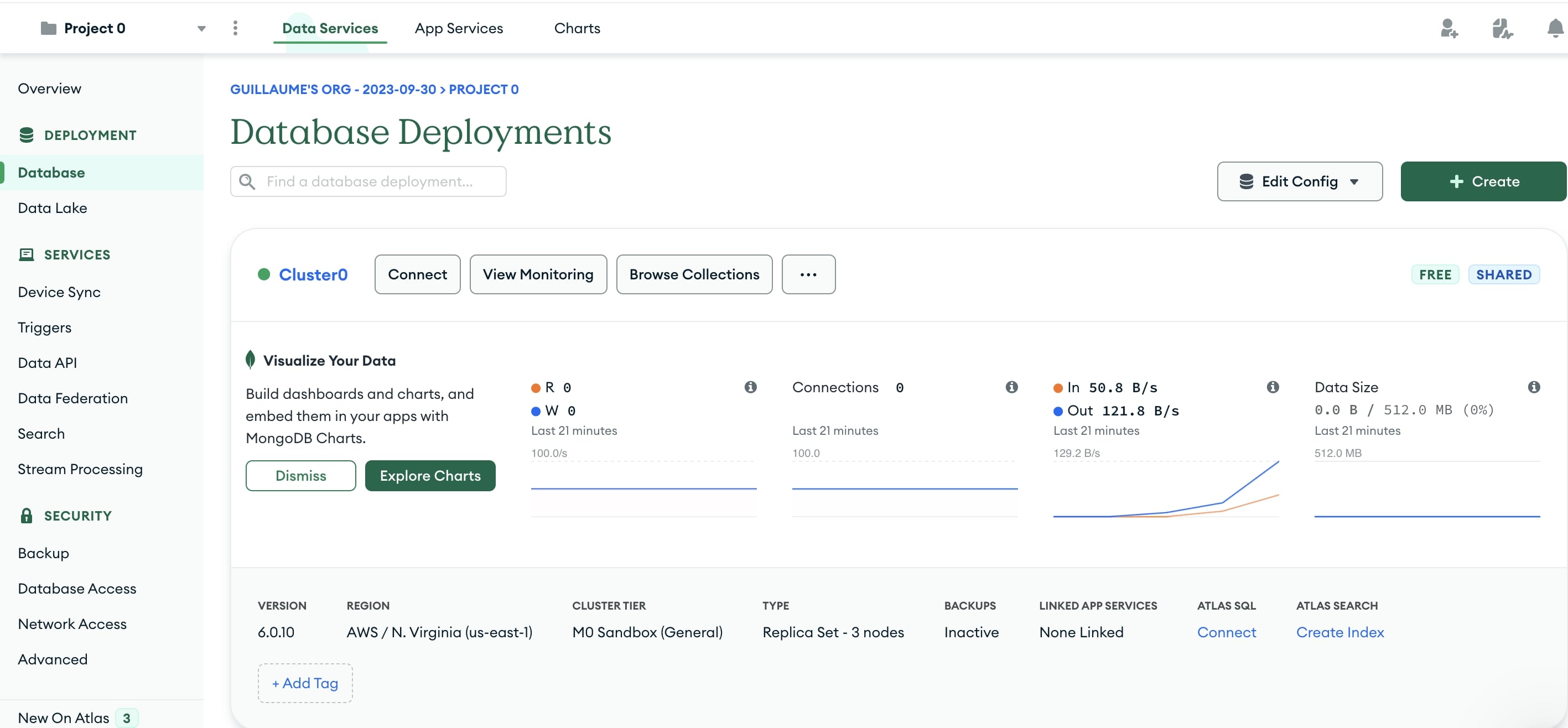
-
Dies öffnet den Abschnitt Collections. Klicken Sie auf die Schaltfläche Add My Own Data.
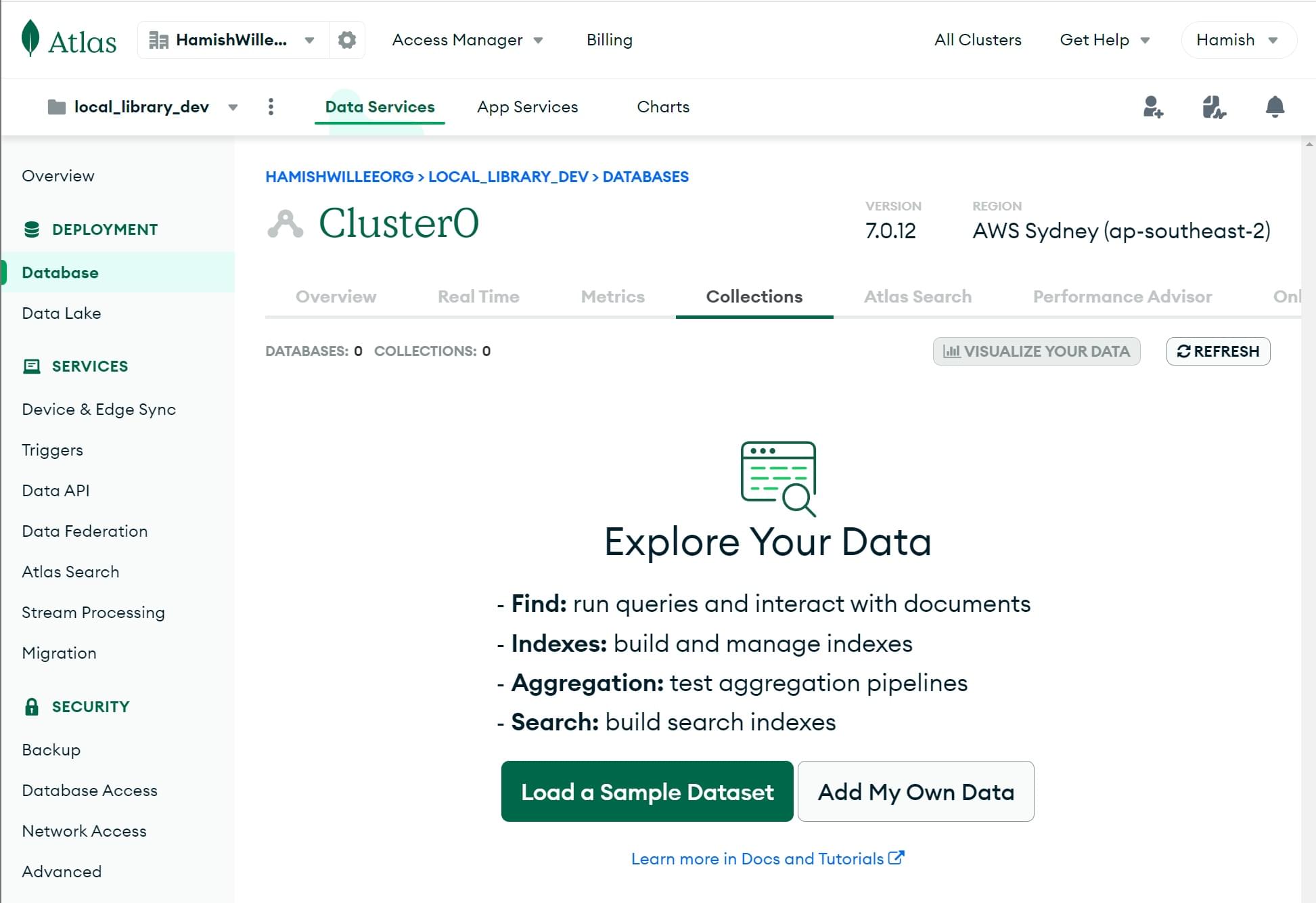
-
Dies öffnet den Bildschirm Create Database.
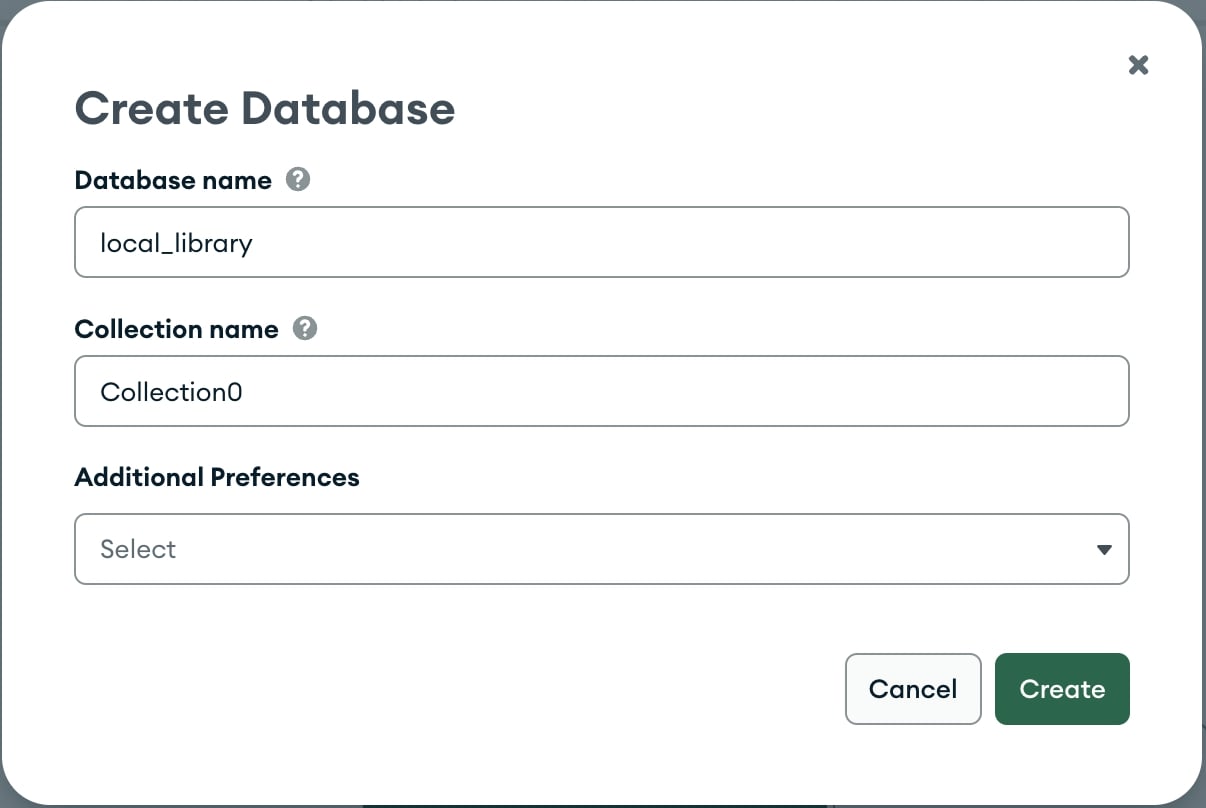
- Geben Sie den Namen für die neue Datenbank als
local_libraryein. - Geben Sie den Namen der Sammlung als
Collection0ein. - Klicken Sie auf die Schaltfläche Create, um die Datenbank zu erstellen.
- Geben Sie den Namen für die neue Datenbank als
-
Sie kehren zum Bildschirm Collections mit Ihrer erstellten Datenbank zurück.
- Klicken Sie auf die Registerkarte Overview, um zur Übersicht des Clusters zurückzukehren.
-
Klicken Sie im Cluster0-Bildschirm Overview auf die Schaltfläche Connect.
-
Dies öffnet den Bildschirm Connect to Cluster0.

- Wählen Sie Ihren Datenbankbenutzer aus.
- Wählen Sie die Kategorie Drivers, dann den Driver Node.js und Version wie gezeigt.
- NICHT den Treiber wie vorgeschlagen installieren.
- Klicken Sie auf das Symbol Copy, um den Verbindungsstring zu kopieren.
- Fügen Sie diesen in Ihren lokalen Texteditor ein.
- Ersetzen Sie
<password>-Platzhalter im Verbindungsstring durch das Passwort Ihres Benutzers. - Fügen Sie den Datenbanknamen "local_library" im Pfad vor den Optionen ein (
...mongodb.net/local_library?retryWrites...) - Speichern Sie die Datei, die diesen String enthält, irgendwo sicher.
Sie haben nun die Datenbank erstellt und eine URL (mit Benutzernamen und Passwort), die zum Zugriff darauf verwendet werden kann.
Dies wird in etwa so aussehen: mongodb+srv://your_user_name:your_password@cluster0.cojoign.mongodb.net/local_library?retryWrites=true&w=majority&appName=Cluster0
Mongoose installieren
Öffnen Sie eine Eingabeaufforderung und navigieren Sie zu dem Verzeichnis, in dem Sie Ihre Skeleton Local Library-Website erstellt haben. Geben Sie folgenden Befehl ein, um Mongoose (und seine Abhängigkeiten) zu installieren und es zu Ihrer package.json Datei hinzuzufügen, es sei denn, Sie haben dies bereits beim Lesen des Mongoose Primers oben getan.
npm install mongoose
Verbindung zu MongoDB herstellen
Öffnen Sie /app.js (im Stammverzeichnis Ihres Projekts) und kopieren Sie den folgenden Text unterhalb der Zeile, in der Sie das Express-Anwendungsobjekt deklarieren (nach der Zeile const app = express();).
Ersetzen Sie den Datenbank-URL-String ('insert_your_database_url_here') durch den Standort-URL, der Ihre eigene Datenbank repräsentiert (d.h. mit den Informationen von MongoDB Atlas).
// Set up mongoose connection
const mongoose = require("mongoose");
mongoose.set("strictQuery", false);
const mongoDB = "insert_your_database_url_here";
main().catch((err) => console.log(err));
async function main() {
await mongoose.connect(mongoDB);
}
Wie im Mongoose Primer oben besprochen, erstellt dieser Code die Standardverbindung zur Datenbank und meldet alle Fehler an die Konsole.
Beachten Sie, dass das Hardcodieren von Datenbankanmeldeinformationen im Quellcode, wie oben gezeigt, nicht empfohlen wird. Wir tun es hier, weil es den Kernverbindungscode zeigt und weil es während der Entwicklung keine signifikante Gefahr gibt, dass das Weitergeben dieser Details sensible Informationen öffnet oder beschädigt. Wir werden Ihnen zeigen, wie dies sicherer geht, wenn die Implementierung in die Produktion erfolgt!
Definition des LocalLibrary-Schemas
Wir werden ein separates Modul für jedes Modell definieren, wie oben besprochen. Beginnen Sie damit, einen Ordner für unsere Modelle im Projektstamm (/models) zu erstellen und dann für jedes der Modelle separate Dateien zu erstellen:
/express-locallibrary-tutorial // the project root
/models
author.js
book.js
bookinstance.js
genre.js
Autor-Modell
Kopieren Sie den Author Schema-Code, der unten gezeigt wird, und fügen Sie ihn in Ihre Datei ./models/author.js ein.
Das Schema definiert einen Autor als String SchemaTypes für den Vor- und Nachnamen (erforderlich, mit maximal 100 Zeichen) und Date Felder für Geburts- und Sterbedaten.
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const AuthorSchema = new Schema({
first_name: { type: String, required: true, maxLength: 100 },
family_name: { type: String, required: true, maxLength: 100 },
date_of_birth: { type: Date },
date_of_death: { type: Date },
});
// Virtual for author's full name
AuthorSchema.virtual("name").get(function () {
// To avoid errors in cases where an author does not have either a family name or first name
// We want to make sure we handle the exception by returning an empty string for that case
let fullname = "";
if (this.first_name && this.family_name) {
fullname = `${this.family_name}, ${this.first_name}`;
}
return fullname;
});
// Virtual for author's URL
AuthorSchema.virtual("url").get(function () {
// We don't use an arrow function as we'll need the this object
return `/catalog/author/${this._id}`;
});
// Export model
module.exports = mongoose.model("Author", AuthorSchema);
Wir haben auch eine virtuelle Eigenschaft für das AuthorSchema namens "url" deklariert, die die absolute URL zurückgibt, die benötigt wird, um eine bestimmte Instanz des Modells zu erhalten — wir verwenden die Eigenschaft in unseren Vorlagen, wann immer wir einen Link zu einem bestimmten Autor erhalten müssen.
Hinweis: Das Deklarieren unserer URLs als virtuell im Schema ist eine gute Idee, denn dann muss die URL für ein Element nur an einer Stelle geändert werden. Zum jetzigen Zeitpunkt würde ein Link mit dieser URL nicht funktionieren, da wir keinen Routing-Code für individuelle Modellinstanzen haben. Wir werden dies in einem späteren Artikel einrichten!
Am Ende des Moduls exportieren wir das Modell.
Buch-Modell
Kopieren Sie den Book Schema-Code, der unten gezeigt wird, und fügen Sie ihn in Ihre Datei ./models/book.js ein.
Der Großteil davon ist dem Autor-Modell ähnlich — wir haben ein Schema mit mehreren String-Feldern und einer Virtuellen Eigenschaft für das Abrufen der URL spezifischer Buchdatensätze deklariert und haben das Modell exportiert.
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const BookSchema = new Schema({
title: { type: String, required: true },
author: { type: Schema.Types.ObjectId, ref: "Author", required: true },
summary: { type: String, required: true },
isbn: { type: String, required: true },
genre: [{ type: Schema.Types.ObjectId, ref: "Genre" }],
});
// Virtual for book's URL
BookSchema.virtual("url").get(function () {
// We don't use an arrow function as we'll need the this object
return `/catalog/book/${this._id}`;
});
// Export model
module.exports = mongoose.model("Book", BookSchema);
Der Hauptunterschied hier ist, dass wir zwei Referenzen zu anderen Modellen erstellt haben:
- Autor ist eine Referenz auf ein einzelnes
AuthorModellobjekt und ist erforderlich. - Genre ist eine Referenz auf ein Array von
GenreModellobjekten. Dieses Objekt haben wir noch nicht deklariert!
Buchinstanz-Modell
Kopieren Sie schließlich den Schema-Code der BookInstance, der unten gezeigt wird, und fügen Sie ihn in Ihre Datei ./models/bookinstance.js ein.
Die BookInstance repräsentiert ein spezifisches Exemplar eines Buches, das jemand ausleihen könnte und enthält Informationen darüber, ob die Kopie verfügbar ist, an welchem Datum sie voraussichtlich zurückgegeben wird und "Impressum" (oder Versions-) Details.
const mongoose = require("mongoose");
const Schema = mongoose.Schema;
const BookInstanceSchema = new Schema({
book: { type: Schema.Types.ObjectId, ref: "Book", required: true }, // reference to the associated book
imprint: { type: String, required: true },
status: {
type: String,
required: true,
enum: ["Available", "Maintenance", "Loaned", "Reserved"],
default: "Maintenance",
},
due_back: { type: Date, default: Date.now },
});
// Virtual for bookinstance's URL
BookInstanceSchema.virtual("url").get(function () {
// We don't use an arrow function as we'll need the this object
return `/catalog/bookinstance/${this._id}`;
});
// Export model
module.exports = mongoose.model("BookInstance", BookInstanceSchema);
Die neuen Dinge, die wir hier zeigen, sind die Feldoptionen:
enum: Dies erlaubt es uns, die erlaubten Werte eines Strings festzulegen. In diesem Fall verwenden wir es, um den Verfügbarkeitsstatus unserer Bücher anzugeben (die Verwendung eines Enums ermöglicht es uns, falsche Schreibweisen und beliebige Werte für unseren Status zu vermeiden).default: Wir verwenden die Voreinstellung, um den Standardstatus für neu erstellte Buchinstanzen auf "Wartung" zu setzen und das Standard-due_back-Datum aufjetzt(beachten Sie, wie Sie die Date-Funktion beim Setzen des Datums aufrufen können!).
Alles andere sollte aus unseren vorherigen Schemata bekannt sein.
Genre-Modell - Herausforderung
Öffnen Sie Ihre Datei ./models/genre.js und erstellen Sie ein Schema zum Speichern von Genres (die Kategorie des Buches, z.B. ob es Fiktion oder Sachbuch, Romanze oder Militärgeschichte ist).
Die Definition wird den anderen Modellen sehr ähnlich sein:
- Das Modell sollte einen
StringSchemaType namensnamehaben, um das Genre zu beschreiben. - Der Name sollte erforderlich sein und zwischen 3 und 100 Zeichen haben.
- Deklarieren Sie eine Virtuelle Eigenschaft für die URL des Genres, benannt
url. - Exportieren Sie das Modell.
Testen — einige Artikel erstellen
Das war's. Wir haben jetzt alle Modelle für die Website eingerichtet!
Um die Modelle zu testen (und einige Beispielbücher und andere Artikel zu erstellen, die wir in unseren nächsten Artikeln verwenden können), werden wir nun ein unabhängiges Skript ausführen, um Artikel von jedem Typ zu erstellen:
-
Laden Sie (oder erstellen Sie anderweitig) die Datei populatedb.js herunter, innerhalb Ihres express-locallibrary-tutorial Verzeichnisses (im selben Verzeichnis wie
package.json).Hinweis: Der Code in
populatedb.jskann beim Lernen von JavaScript nützlich sein, aber das Verständnis davon ist für dieses Tutorial nicht erforderlich. -
Führen Sie das Skript mit node in Ihrer Eingabeaufforderung aus und geben Sie die URL Ihrer MongoDB Datenbank (die gleiche, die Sie als Platzhalter insert_your_database_url_here im
app.jsfrüher ersetzt haben) an:bashnode populatedb <your MongoDB url>Hinweis: Unter Windows müssen Sie die Datenbank-URL in doppelte (") Anführungszeichen setzen. Unter anderen Betriebssystemen benötigen Sie möglicherweise einfache (') Anführungszeichen.
-
Das Skript sollte bis zum Abschluss durchlaufen werden und Elemente erstellen, während es sie im Terminal anzeigt.
Hinweis: Gehen Sie zu Ihrer Datenbank auf MongoDB Atlas (im Tab Collections). Sie sollten jetzt in der Lage sein, in einzelne Sammlungen von Büchern, Autoren, Genres und Buchinstanzen hineinzugehen und einzelne Dokumente zu überprüfen.
Zusammenfassung
In diesem Artikel haben wir ein wenig über Datenbanken und ORMs auf Node/Express gelernt und viel darüber, wie Mongoose Schema und Modelle definiert werden. Wir haben diese Informationen genutzt, um Book, BookInstance, Author und Genre Modelle für die LocalLibrary Website zu entwerfen und zu implementieren.
Zuletzt haben wir unsere Modelle getestet, indem wir eine Reihe von Instanzen erstellt haben (unter Verwendung eines eigenständigen Skripts). Im nächsten Artikel werden wir uns mit der Erstellung einiger Seiten befassen, um diese Objekte anzuzeigen.
Siehe auch
- Datenbankintegration (Express-Dokumentation)
- Mongoose Website (Mongoose-Dokumentation)
- Mongoose Leitfaden (Mongoose-Dokumentation)
- Validierung (Mongoose-Dokumentation)
- Schema-Typen (Mongoose-Dokumentation)
- Modelle (Mongoose-Dokumentation)
- Abfragen (Mongoose-Dokumentation)
- Population (Mongoose-Dokumentation)