Debugging HTML
Hinweis: Der Inhalt dieses Artikels ist derzeit unvollständig, entschuldigen Sie bitte! Wir arbeiten hart daran, den MDN-Web-Entwicklungsbereich zu verbessern, und wir werden die als unvollständig markierten Bereiche ("TODO") bald abschließen.
HTML zu schreiben ist in Ordnung, aber was, wenn etwas schief geht und Sie nicht herausfinden können, wo der Fehler im Code ist? Dieser Artikel wird Ihnen einige Werkzeuge vorstellen, die Ihnen helfen können, Fehler in HTML zu finden und zu beheben.
| Voraussetzungen: | Grundlegende HTML-Kenntnisse, wie sie in Grundlegende HTML-Syntax behandelt werden. Textlevel-Semantik wie Überschriften und Absätze und Listen. Strukturelles HTML. |
|---|---|
| Ziel: |
|
Debugging ist nicht beängstigend
Wenn Sie Code jeglicher Art schreiben, ist normalerweise alles in Ordnung, bis zu dem gefürchteten Moment, in dem ein Fehler auftritt — Sie haben etwas falsch gemacht, sodass Ihr Code nicht funktioniert — entweder gar nicht oder nicht ganz so, wie Sie es sich gewünscht haben. Das folgende Beispiel zeigt einen Fehler, der beim Versuch, ein einfaches Programm in der Rust Sprache zu kompilieren, gemeldet wird.

Hier ist die Fehlermeldung relativ leicht verständlich — "nicht abgeschlossenes doppeltes Anführungszeichen". Wenn Sie sich das Listing ansehen, können Sie wahrscheinlich erkennen, dass println!(Hello, world!"); möglicherweise ein doppeltes Anführungszeichen fehlt. Fehlermeldungen können jedoch schnell komplizierter und weniger leicht zu interpretieren werden, wenn Programme größer werden, und selbst einfache Fälle können für jemanden, der nichts über Rust weiß, etwas einschüchternd wirken.
Debugging muss jedoch nicht beängstigend sein — der Schlüssel, um sich beim Schreiben und Debuggen jeder Programmiersprache oder jedes Codes wohlzufühlen, ist die Vertrautheit mit sowohl der Sprache als auch den Tools.
HTML und Debugging
HTML ist nicht so kompliziert zu verstehen wie Rust. HTML wird nicht vor der Interpretation durch den Browser in eine andere Form kompiliert und zeigt das Ergebnis an (es wird interpretiert, nicht kompiliert). Und die Element-Syntax von HTML ist arguably viel einfacher zu verstehen als bei einer "echten Programmiersprache" wie Rust, JavaScript oder Python. Die Art und Weise, wie Browser HTML parsen, ist viel permessiver als die Ausführung von Programmiersprachen, was sowohl gut als auch schlecht ist.
Permissiver Code
Was meinen wir also mit permissiv? Nun, im Allgemeinen gibt es, wenn Sie etwas im Code falsch machen, zwei Hauptarten von Fehlern, auf die Sie stoßen werden:
- Syntaxfehler: Dies sind Schreib- oder Interpunktionsfehler in Ihrem Code, die tatsächlich dazu führen, dass das Programm nicht ausgeführt wird, wie der oben gezeigte Rust-Fehler. Diese sind normalerweise einfach zu beheben, solange Sie mit der Syntax der Sprache vertraut sind und wissen, was die Fehlermeldungen bedeuten.
- Logikfehler: Dies sind Fehler, bei denen die Syntax tatsächlich korrekt ist, der Code jedoch nicht das ist, was Sie beabsichtigt haben, was bedeutet, dass das Programm falsch ausgeführt wird. Diese sind oft schwerer zu beheben als Syntaxfehler, da es keine Fehlermeldung gibt, die Sie zur Fehlerquelle führt.
HTML selbst leidet nicht unter Syntaxfehlern, da Browser es permissiv parsen, was bedeutet, dass die Seite auch bei Syntaxfehlern angezeigt wird. Browser haben eingebaute Regeln, um festzulegen, wie falsch geschriebenes Markup interpretiert werden soll, sodass etwas ausgeführt wird, selbst wenn es nicht das ist, was Sie erwartet haben. Dies kann natürlich immer noch ein Problem sein!
Hinweis: HTML wird permissiv geparst, weil bei der ersten Erstellung des Webs entschieden wurde, dass es wichtiger ist, den Menschen zu ermöglichen, ihre Inhalte zu veröffentlichen, als sicherzustellen, dass die Syntax absolut korrekt ist. Das Web wäre wahrscheinlich nicht so populär geworden, wie es heute ist, wenn es von Anfang an strenger gewesen wäre.
Aktives Lernen: Studium von permissivem Code
Es ist an der Zeit, die permissive Natur von HTML-Code zu studieren.
-
Laden Sie zuerst unser debug-example Demo herunter und speichern Sie es lokal. Dieses Demo ist absichtlich mit einigen eingebauten Fehlern geschrieben, die wir untersuchen werden (das HTML-Markup wird als schlecht-formatiert bezeichnet, im Gegensatz zu gut-formatiert).
-
Öffnen Sie es als nächstes in einem Browser. Sie werden etwas Ähnliches sehen wie dies:

-
Dies sieht sofort nicht gut aus; sehen wir uns den Quellcode an, um zu sehen, ob wir herausfinden können, warum (nur der Body-Inhalt wird gezeigt):
html<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> -
Überprüfen wir die Probleme:
- Die Absatz- und Listenelement-Elemente haben keine Schlusstags. Beim Blick auf das obige Bild scheint dies das Markup-Rendering nicht allzu sehr beeinträchtigt zu haben, da es leicht ist, zu bestimmen, wo ein Element enden und ein anderes beginnen sollte.
- Das erste
<strong>-Element hat kein Schlusstag. Dies ist etwas problematischer, da es nicht einfach ist zu sagen, wo das Element enden soll. Tatsächlich wurde der ganze restliche Text stark betont. - Dieser Abschnitt ist schlecht geschachtelt:
<strong>strong <em>strong emphasized?</strong> what is this?</em>. Es ist nicht einfach zu sagen, wie dies interpretiert wurde, wegen des vorherigen Problems. - Der
href-Attributwert fehlt ein abschließendes doppeltes Anführungszeichen. Dies scheint das größte Problem verursacht zu haben — der Link wurde überhaupt nicht gerendert.
-
Schauen wir uns nun das Markup an, das vom Browser gerendert wurde, im Gegensatz zu dem in dem Quellcode. Um dies zu tun, können wir die Entwicklerwerkzeuge des Browsers verwenden. Wenn Sie mit der Verwendung der Entwicklerwerkzeuge Ihres Browsers nicht vertraut sind, nehmen Sie sich ein paar Minuten Zeit und lesen Sie den Artikel Entdecken Sie die Entwicklerwerkzeuge des Browsers.
-
Im DOM-Inspektor können Sie sehen, wie das gerenderte Markup aussieht:

-
Mithilfe des DOM-Inspektors schauen wir uns unseren Code im Detail an, um zu sehen, wie der Browser versucht hat, unsere HTML-Fehler zu beheben (wir haben die Untersuchung in Firefox durchgeführt; andere moderne Browser sollten dasselbe Ergebnis liefern):
-
Die Absätze und Listenelemente wurden mit Schlusstags versehen.
-
Es ist nicht klar, wo das erste
<strong>-Element geschlossen werden soll, daher hat der Browser jeden separaten Textblock mit einem eigenen strong-Tag umschlossen, bis ganz nach unten im Dokument. -
Die falsche Verschachtelung wurde vom Browser wie hier gezeigt behoben:
html<strong> strong <em>strong emphasized?</em> </strong> <em> what is this?</em> -
Der Link mit dem fehlenden doppelten Anführungszeichen wurde vollständig gelöscht. Das letzte Listenelement sieht so aus:
html<li> <strong> Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
-
HTML-Validierung
Wie Sie aus dem obigen Beispiel sehen können, möchten Sie wirklich sicherstellen, dass Ihr HTML gut-formatiert ist! Aber wie? Bei einem kleinen Beispiel wie dem oben gezeigten ist es einfach, die Zeilen zu durchsuchen und die Fehler zu finden, aber was ist mit einem großen, komplexen HTML-Dokument?
Die beste Strategie besteht darin, Ihre HTML-Seite durch den Markup-Validierungsdienst laufen zu lassen — erstellt und gepflegt vom W3C, der Organisation, die sich um die Spezifikationen kümmert, die HTML, CSS und andere Webtechnologien definieren. Diese Webseite nimmt ein HTML-Dokument als Eingabe an, geht es durch und gibt Ihnen einen Bericht, der Ihnen mitteilt, was mit Ihrem HTML falsch ist.

Um das zu validierende HTML anzugeben, können Sie eine Webadresse angeben, eine HTML-Datei hochladen oder direkt etwas HTML-Code eingeben.
Aktives Lernen: Validieren eines HTML-Dokuments
Probieren wir dies mit unserem Beispieldokument aus.
- Laden Sie zuerst den Markup-Validierungsdienst in einem Browser-Tab, falls er noch nicht geöffnet ist.
- Wechseln Sie zum Tab Über direkten Eingabemodus validieren.
- Kopieren Sie den gesamten Code des Beispieldokuments (nicht nur den Body) und fügen Sie ihn in den großen Textbereich ein, der im Markup-Validierungsdienst angezeigt wird.
- Drücken Sie die Schaltfläche Check.
Dies sollte Ihnen eine Liste von Fehlern und anderen Informationen geben.
Die Fehlermeldungen interpretieren
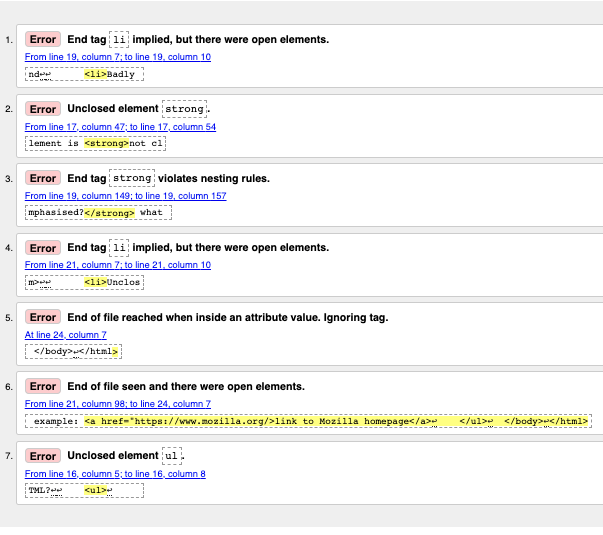
Die Fehlermeldungen sind normalerweise hilfreich, manchmal sind sie jedoch nicht so hilfreich; mit ein wenig Übung können Sie lernen, diese zu interpretieren, um Ihren Code zu beheben. Gehen wir die Fehlermeldungen durch und sehen wir, was sie bedeuten. Sie werden sehen, dass jede Meldung mit einer Zeilen- und Spaltennummer versehen ist, die Ihnen hilft, den Fehler leicht zu lokalisieren.
-
"End-Tag
liimpliziert, aber es gab offene Elemente" (2 Instanzen): Diese Meldungen weisen darauf hin, dass ein Element geöffnet bleibt, das geschlossen werden sollte. Das End-Tag wird impliziert, ist aber tatsächlich nicht vorhanden. Die Zeilen-/Spalteninformationen weisen auf die erste Zeile nach der Zeile hin, in der das End-Tag wirklich sein sollte, aber dies ist ein ausreichender Hinweis, um zu sehen, was falsch ist. -
"Nicht geschlossenes Element
strong": Dies ist wirklich einfach zu verstehen — ein<strong>-Element ist nicht geschlossen, und die Zeilen-/Spalteninformationen zeigen genau darauf, wo es ist. -
"End-Tag
strongverletzt Verschachtelungsregeln": Dies weist auf die falsch geschachtelten Elemente hin, und die Zeilen-/Spalteninformationen zeigen, wo sie sich befinden. -
"Dateiende erreicht, während innerhalb eines Attributwerts. Tag wird ignoriert": Dies ist etwas kryptisch; es bezieht sich darauf, dass ein Attributwert irgendwo nicht richtig gebildet ist, möglicherweise in der Nähe des Endes der Datei, weil das Ende der Datei innerhalb des Attributwerts zu liegen scheint. Die Tatsache, dass der Browser den Link nicht rendert, sollte uns einen guten Hinweis darauf geben, welches Element schuld ist.
-
"Ende der Datei erreicht und es gab offene Elemente": Das ist etwas zweideutig, bezieht sich jedoch darauf, dass es offene Elemente gibt, die ordnungsgemäß geschlossen werden müssen. Die Zeilennummern weisen auf die letzten Zeilen der Datei hin, und diese Fehlermeldung ist mit einer Codezeile versehen, die ein Beispiel für ein offenes Element zeigt:
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Hinweis: Ein Attribut, dem ein abschließendes Anführungszeichen fehlt, kann zu einem offenen Element führen, da der Rest des Dokuments als Inhalt des Attributs interpretiert wird.
-
"Nicht geschlossenes Element
ul": Dies ist nicht sehr hilfreich, da das<ul>-Element korrekt geschlossen wurde. Dieser Fehler tritt auf, weil das<a>-Element aufgrund des fehlenden abschließenden Anführungszeichens nicht geschlossen ist.
Wenn Sie nicht herausfinden können, was jede Fehlermeldung bedeutet, machen Sie sich keine Sorgen — eine gute Idee ist, einige Fehler gleichzeitig zu beheben. Versuchen Sie dann, Ihr HTML erneut zu validieren, um zu zeigen, welche Fehler noch vorhanden sind. Manchmal wird durch das Beheben eines früheren Fehlers auch andere Fehlermeldungen beseitigt — mehrere Fehler können oft durch ein einziges Problem verursacht werden, in einem Dominoeffekt.
Sie werden wissen, dass alle Ihre Fehler behoben sind, wenn Sie das folgende Banner in Ihrer Ausgabe sehen:
![]()
Verwendung eines DOM-Inspektors
TODO
Zusammenfassung
Damit haben wir eine Einführung in das Debuggen von HTML, die Ihnen einige nützliche Fähigkeiten bietet, auf die Sie sich später in Ihrer Karriere bei der Fehlersuche in CSS, JavaScript und anderen Codearten verlassen können. Dies markiert auch das Ende der Lerneinheit "Einführung in HTML" — jetzt können Sie sich mit unseren Bewertungen testen: Die erste ist unten verlinkt.