HTTP Nachrichten
HTTP-Nachrichten sind der Mechanismus, um Daten zwischen einem Server und einem Client im HTTP-Protokoll auszutauschen. Es gibt zwei Arten von Nachrichten: Anfragen, die vom Client gesendet werden, um eine Aktion auf dem Server auszulösen, und Antworten, die der Server als Antwort auf eine Anfrage sendet.
Entwickler erstellen selten selbst HTTP-Nachrichten von Grund auf. Anwendungen wie ein Browser, ein Proxy oder ein Webserver verwenden Software, die darauf ausgelegt ist, HTTP-Nachrichten auf zuverlässige und effiziente Weise zu erstellen. Wie Nachrichten erstellt oder transformiert werden, wird durch APIs in Browsern, Konfigurationsdateien für Proxys oder Server oder andere Schnittstellen gesteuert.
In den HTTP-Protokollversionen bis HTTP/2 sind Nachrichten textbasiert und relativ einfach zu lesen und zu verstehen, nachdem Sie sich mit dem Format vertraut gemacht haben. In HTTP/2 sind Nachrichten in ein binäres Rahmenformat eingebunden, was das Lesen ohne bestimmte Werkzeuge etwas erschwert. Die zugrunde liegende Semantik des Protokolls bleibt jedoch gleich, sodass Sie die Struktur und Bedeutung von HTTP-Nachrichten basierend auf dem textbasierten Format von HTTP/1.x-Nachrichten lernen und dieses Verständnis auf HTTP/2 und darüber hinaus anwenden können.
Dieser Leitfaden verwendet HTTP/1.1-Nachrichten für die Lesbarkeit und erklärt die Struktur von HTTP-Nachrichten unter Verwendung des HTTP/1.1-Formats. Wir heben einige Unterschiede hervor, die Sie für die Beschreibung von HTTP/2 im letzten Abschnitt benötigen könnten.
Hinweis: Sie können HTTP-Nachrichten im Netzwerk-Tab der Entwickler-Tools eines Browsers sehen oder wenn Sie HTTP-Nachrichten mit CLI-Tools wie curl auf die Konsole drucken, zum Beispiel.
Anatomie einer HTTP-Nachricht
Um zu verstehen, wie HTTP-Nachrichten funktionieren, schauen wir uns HTTP/1.1-Nachrichten an und analysieren die Struktur. Die folgende Abbildung zeigt, wie Nachrichten in HTTP/1.1 aussehen:

Sowohl Anfragen als auch Antworten haben eine ähnliche Struktur:
- Eine Startzeile ist eine einzelne Zeile, die die HTTP-Version zusammen mit der Anfragemethode oder dem Ergebnis der Anfrage beschreibt.
- Ein optionaler Satz von HTTP-Headern enthält Metadaten, die die Nachricht beschreiben. Zum Beispiel könnte eine Anfrage für eine Ressource die erlaubten Formate dieser Ressource einschließen, während die Antwort Header enthalten könnte, um das tatsächlich zurückgegebene Format anzuzeigen.
- Eine leere Zeile, die anzeigt, dass die Metadaten der Nachricht abgeschlossen sind.
- Ein optionaler Body, der Daten enthält, die mit der Nachricht verknüpft sind. Dies könnte zum Beispiel POST-Daten sein, die an den Server in einer Anfrage gesendet werden, oder eine Ressource, die dem Client in einer Antwort zurückgegeben wird. Ob eine Nachricht einen Body enthält oder nicht, wird durch die Startzeile und HTTP-Header bestimmt.
Die Startzeile und die Header der HTTP-Nachricht werden zusammen als der Head der Anfragen bezeichnet, und der Teil danach, der den Inhalt enthält, wird als Body bezeichnet.
HTTP-Anfragen
Betrachten wir das folgende Beispiel einer HTTP POST-Anfrage, die gesendet wird, nachdem ein Benutzer ein Formular auf einer Webseite abgeschickt hat:
POST /users HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 50
name=FirstName%20LastName&email=bsmth%40example.com
Die Startzeile in HTTP/1.x-Anfragen (POST /users HTTP/1.1 im obigen Beispiel) wird als "Request-Line" bezeichnet und besteht aus drei Teilen:
<method> <request-target> <protocol>
<method>-
Die HTTP-Methode (auch bekannt als ein HTTP-Verb) ist eines von mehreren definierten Wörtern, die die Bedeutung der Anfrage und das gewünschte Ergebnis beschreiben. Zum Beispiel gibt
GETan, dass der Client im Gegenzug eine Ressource erhalten möchte, undPOSTbedeutet, dass der Client Daten an einen Server sendet. <request-target>-
Das Anforderungsziel ist in der Regel eine absolute oder relative URL und wird durch den Kontext der Anfrage charakterisiert. Das Format des Anforderungsziels hängt von der verwendeten HTTP-Methode und dem Kontext der Anfrage ab. Es wird im Abschnitt Anforderungsziele unten detaillierter beschrieben.
<protocol>-
Die HTTP-Version, die die Struktur der restlichen Nachricht definiert und als Indikator dafür dient, welche Version für die Antwort erwartet wird. Dies ist fast immer
HTTP/1.1, daHTTP/0.9undHTTP/1.0veraltet sind. In HTTP/2 und darüber hinaus ist die Protokollversion nicht in Nachrichten enthalten, da sie aus dem Verbindungsaufbau verstanden wird.
Anforderungsziele
Es gibt einige Möglichkeiten, ein Anforderungsziel zu beschreiben, aber bei weitem die häufigste ist die "Ursprungsform". Hier ist eine Liste der Zieltypen und wann sie verwendet werden:
-
In Ursprungsform kombiniert der Empfänger einen absoluten Pfad mit den Informationen im
Host-Header. Eine Abfragezeichenfolge kann dem Pfad für zusätzliche Informationen angehängt werden (in der Regel im Formatkey=value). Dies wird mit den MethodenGET,POST,HEADundOPTIONSverwendet:httpGET /en-US/docs/Web/HTTP/Messages HTTP/1.1 -
Die absolute Form ist eine vollständige URL, die die Autorität einschließt, und wird mit
GETverwendet, wenn eine Verbindung zu einem Proxy hergestellt wird:httpGET https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 -
Die Autoritätsform ist die Autorität und der Port, getrennt durch einen Doppelpunkt (
:). Sie wird nur mit der MethodeCONNECTverwendet, wenn ein HTTP-Tunnel eingerichtet wird:httpCONNECT developer.mozilla.org:443 HTTP/1.1 -
Die Sternchenform wird nur mit
OPTIONSverwendet, wenn Sie den Server als Ganzes (*) im Gegensatz zu einer benannten Ressource darstellen möchten:httpOPTIONS * HTTP/1.1
Anfrage-Header
Header sind Metadaten, die mit einer Anfrage nach der Startzeile und vor dem Body gesendet werden. Im obigen Formularübermittlungsbeispiel sind dies die folgenden Zeilen der Nachricht:
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 50
In HTTP/1.x ist jeder Header ein nicht-case-sensitiver String, gefolgt von einem Doppelpunkt (:) und einem Wert, dessen Format vom Header abhängt.
Der gesamte Header, einschließlich des Werts, besteht aus einer einzigen Zeile.
Diese Zeile kann in einigen Fällen ziemlich lang sein, wie beim Cookie-Header.

Einige Header werden ausschließlich in Anfragen verwendet, während andere sowohl in Anfragen als auch in Antworten gesendet werden können oder eine spezifischere Kategorisierung haben:
- Anfrage-Header bieten zusätzlichen Kontext zu einer Anfrage oder fügen zusätzliche Logik hinzu, wie diese von einem Server behandelt werden sollte (z.B. bedingte Anfragen).
- Repräsentations-Header werden in einer Anfrage gesendet, wenn die Nachricht einen Body hat, und sie beschreiben die ursprüngliche Form der Nachrichtendaten und jede angewandte Kodierung. Dies ermöglicht dem Empfänger zu verstehen, wie die Ressource wiederhergestellt wird, wie sie war, bevor sie über das Netzwerk gesendet wurde.
Anfrage-Body
Der Anfrage-Body ist der Teil einer Anfrage, der Informationen an den Server überträgt.
Nur PATCH, POST und PUT Anfragen haben einen Body.
Im Formularübermittlungsbeispiel ist dieser Teil der Body:
name=FirstName%20LastName&email=bsmth%40example.com
Der Body in der Formularübermittlungsanfrage enthält eine relativ kleine Menge von Informationen als key=value Paare, aber ein Anfrage-Body könnte andere Datentypen enthalten, die der Server erwartet:
{
"firstName": "Brian",
"lastName": "Smith",
"email": "bsmth@example.com",
"more": "data"
}
oder Daten in mehreren Teilen:
--delimiter123
Content-Disposition: form-data; name="field1"
value1
--delimiter123
Content-Disposition: form-data; name="field2"; filename="example.txt"
Text file contents
--delimiter123--
HTTP-Antworten
Antworten sind die HTTP-Nachrichten, die ein Server als Antwort auf eine Anfrage sendet.
Die Antwort teilt dem Client mit, was das Ergebnis der Anfrage war.
Hier ist ein Beispiel einer HTTP/1.1-Antwort auf eine POST-Anfrage, die einen neuen Benutzer erstellt hat:
HTTP/1.1 201 Created
Content-Type: application/json
Location: http://example.com/users/123
{
"message": "New user created",
"user": {
"id": 123,
"firstName": "Example",
"lastName": "Person",
"email": "bsmth@example.com"
}
}
Die Startzeile (HTTP/1.1 201 Created oben) wird in Antworten als "Statuszeile" bezeichnet und hat drei Teile:
<protocol> <status-code> <status-text>
<protocol>-
Die HTTP-Version der restlichen Nachricht.
<status-code>-
Ein numerischer Statuscode, der angibt, ob die Anfrage erfolgreich war oder fehlgeschlagen ist. Häufige Statuscodes sind
200,404oder302. <status-text>-
Der Status-Text ist eine kurze, rein informative, Textbeschreibung des Statuscodes, um einem Menschen zu helfen, die HTTP-Nachricht zu verstehen.
Antwort-Header
Antwort-Header sind die Metadaten, die mit einer Antwort gesendet werden.
In HTTP/1.x ist jeder Header ein nicht-case-sensitiver String, gefolgt von einem Doppelpunkt (:) und einem Wert, dessen Format davon abhängt, welcher Header verwendet wird.

Wie bei Anfrage-Headern gibt es viele verschiedene Header, die in Antworten erscheinen können, und sie werden wie folgt kategorisiert:
- Antwort-Header, die zusätzlichen Kontext zur Nachricht bieten oder zusätzliche Logik hinzufügen, wie der Client Folgeanfragen stellen sollte.
Zum Beispiel enthalten Header wie
ServerInformationen über die Serversoftware, währendDateangibt, wann die Antwort generiert wurde. Es gibt auch Informationen über die zurückgegebene Ressource, wie deren Inhaltstyp (Content-Type) oder wie sie zwischengespeichert werden sollte (Cache-Control). - Repräsentations-Header beschreiben, falls die Nachricht einen Body hat, die Form der Nachrichtendaten und jede angewandte Kodierung. Zum Beispiel könnte dieselbe Ressource in einem bestimmten Medientyp wie XML oder JSON formatiert, einer bestimmten Sprache oder geografischen Region lokalisiert und/oder für die Übertragung komprimiert oder anderweitig kodiert werden. Dies ermöglicht einem Empfänger zu verstehen, wie die Ressource wiederhergestellt wird, wie sie vor der Übertragung über das Netzwerk war.
Antwort-Body
Ein Antwort-Body ist in den meisten Nachrichten enthalten, wenn auf einen Client geantwortet wird.
In erfolgreichen Anfragen enthält der Antwort-Body die Daten, die der Client in einer GET-Anfrage angefordert hat.
Wenn es Probleme mit der Anfrage des Clients gibt, ist es üblich, dass der Antwort-Body beschreibt, warum die Anfrage fehlgeschlagen ist, und Hinweise darauf gibt, ob das Problem dauerhaft oder vorübergehend ist.
Antwort-Bodies können sein:
- Einzelressourcen-Bodies, definiert durch die zwei Header:
Content-TypeundContent-Length, oder von unbekannter Länge und in Chunks kodiert mitTransfer-Encodingaufchunkedgesetzt. - Mehrfachressourcen-Bodies, bestehend aus einem Body, der mehrere Teile enthält, von denen jeder ein unterschiedliches Informationsstück enthält. Mehrteilige Bodies sind typischerweise mit HTML-Formularen verbunden, können aber auch als Antwort auf Bereichsanfragen gesendet werden.
Antworten mit einem Statuscode, der die Anfrage beantwortet, ohne dass Nachrichteninhalt enthalten sein muss, wie 201 Created oder 204 No Content, haben keinen Body.
HTTP/2 Nachrichten
HTTP/1.x verwendet textbasierte Nachrichten, die einfach zu lesen und zu konstruieren sind, aber dadurch einige Nachteile haben.
Sie können Nachrichten-Bodies mit gzip oder anderen Kompressionsalgorithmen komprimieren, aber nicht die Header.
Header sind oft ähnlich oder identisch in einer Client-Server-Interaktion, werden aber in aufeinanderfolgenden Nachrichten auf einer Verbindung wiederholt.
Es gibt viele bekannte Methoden, um sich wiederholenden Text sehr effizient zu komprimieren, was eine große Menge an ungenutzten Bandbreitenersparnissen hinterlässt.
HTTP/1.x hat auch ein Problem namens Head-of-Line (HOL) Blocking, bei dem ein Client auf eine Antwort des Servers warten muss, bevor er die nächste Anfrage senden kann. HTTP Pipelining versuchte, dies zu umgehen, aber schlechte Unterstützung und Komplexität bedeuten, dass es selten verwendet wird und schwierig richtig umzusetzen ist. Mehrere Verbindungen müssen geöffnet werden, um Anfragen gleichzeitig zu senden; und warme (etablierte und beschäftigte) Verbindungen sind effizienter als kalte, aufgrund des TCP Slow Start.
In HTTP/1.1, wenn Sie zwei Anfragen parallel stellen möchten, müssen Sie zwei Verbindungen öffnen:
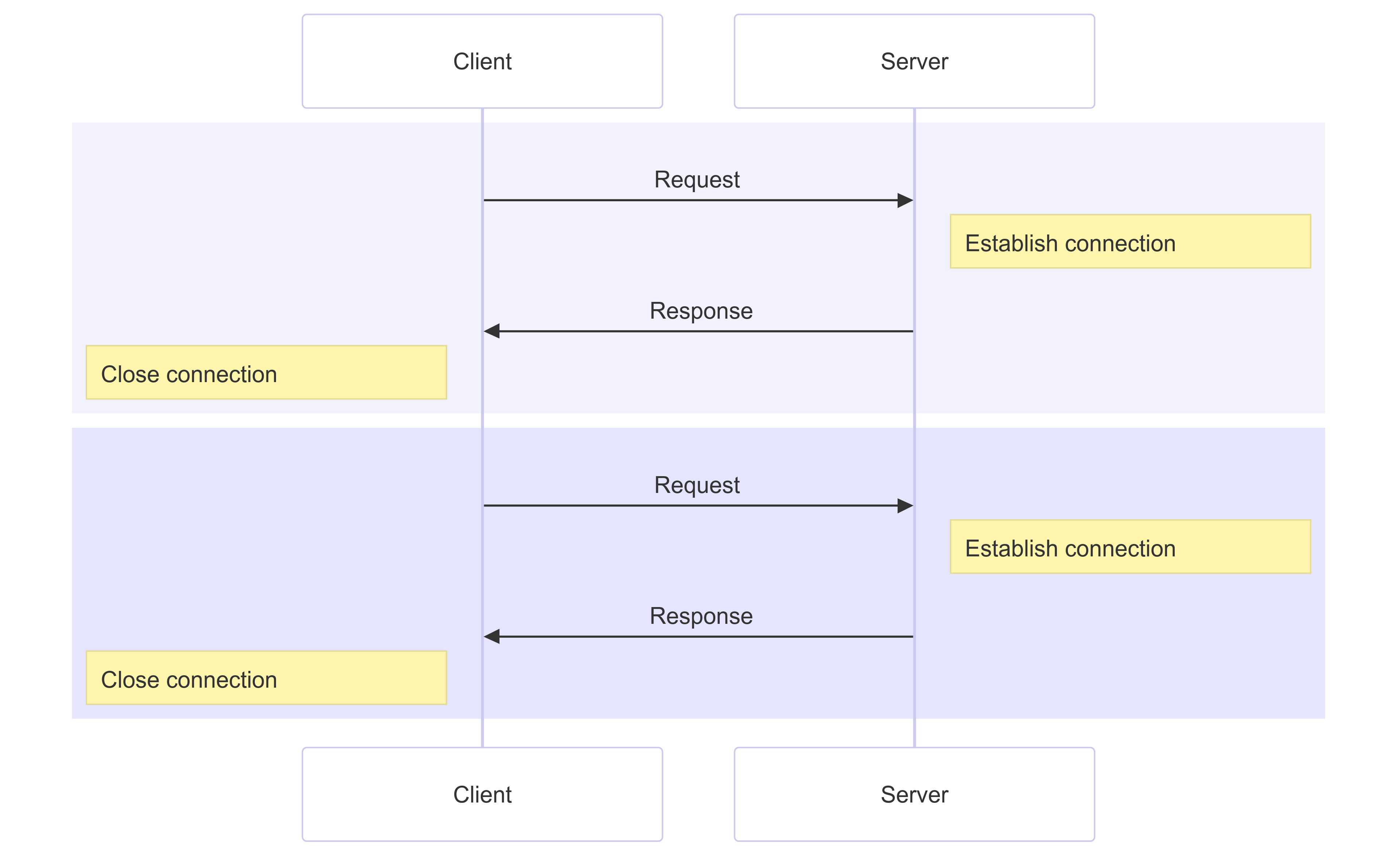
Das bedeutet, dass Browser in der Anzahl der Ressourcen begrenzt sind, die sie gleichzeitig herunterladen und rendern können, was typischerweise auf 6 parallele Verbindungen beschränkt wurde.
HTTP/2 ermöglicht es, eine einzelne TCP-Verbindung für mehrere Anfragen und Antworten gleichzeitig zu nutzen. Dies wird durch das Einpacken von Nachrichten in einen binären Rahmen erreicht, und Senden der Anfragen und Antworten in einem nummerierten Stream auf einer Verbindung. Daten- und Headerrahmen werden getrennt gehandhabt, was es ermöglicht, Header durch einen Algorithmus namens HPACK zu komprimieren. Die gleiche TCP-Verbindung zu nutzen, um mehrere Anfragen gleichzeitig zu bearbeiten, wird Multiplexing genannt.
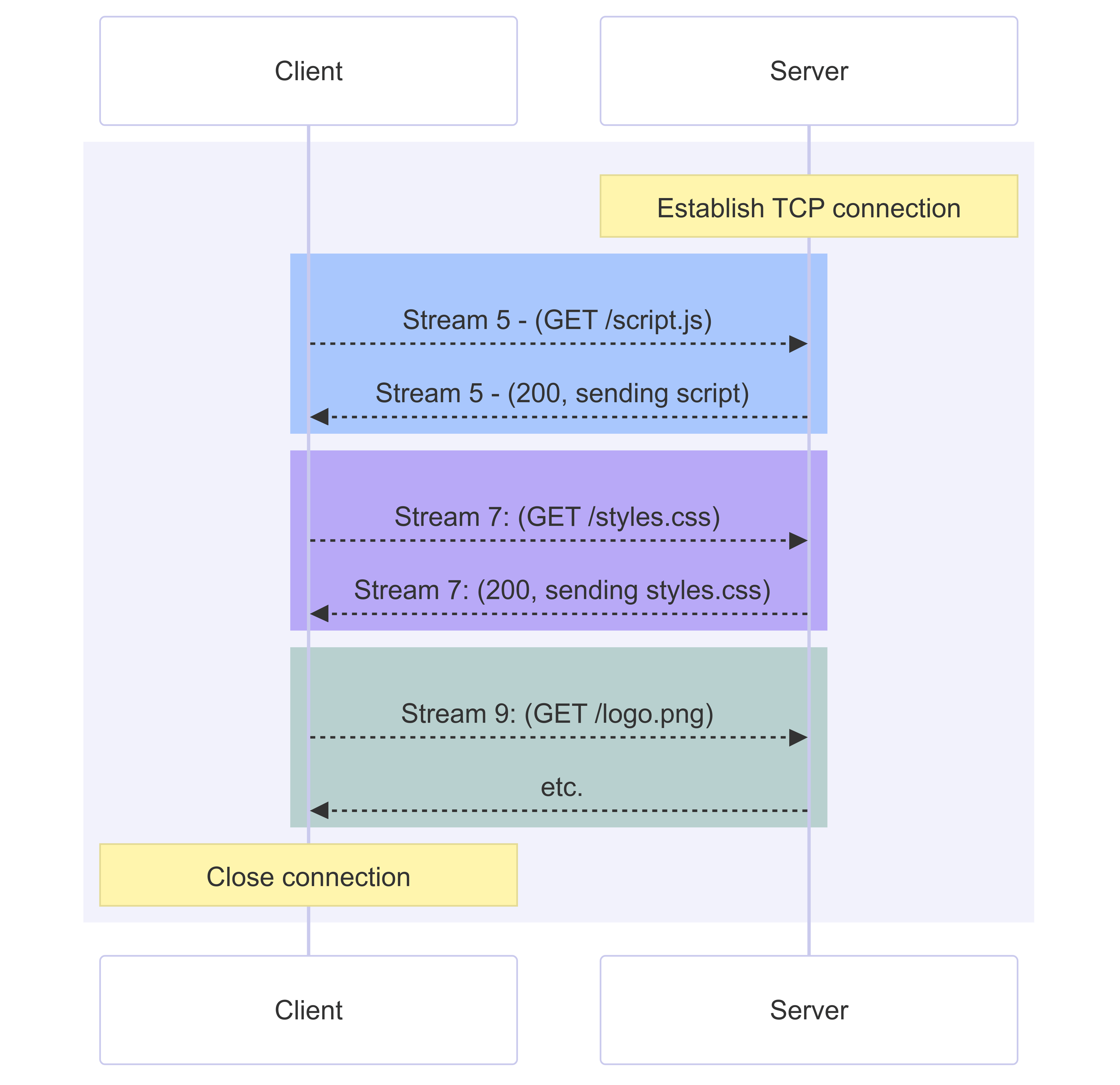
Anfragen müssen nicht unbedingt sequenziell sein: Stream 9 muss nicht auf den Abschluss von Stream 7 warten, zum Beispiel. Die Daten aus mehreren Streams sind auf der Verbindung normalerweise verflochten, sodass Stream 9 und 7 gleichzeitig vom Client empfangen werden können. Es gibt einen Mechanismus für das Protokoll, um eine Priorität für jeden Stream oder jede Ressource festzulegen. Niedrigpriorisierte Ressourcen verbrauchen weniger Bandbreite als höherpriorisierte Ressourcen, wenn sie über verschiedene Streams gesendet werden, oder sie könnten effektiv sequenziell auf der gleichen Verbindung gesendet werden, wenn es kritische Ressourcen gibt, die zuerst behandelt werden sollten.
Im Allgemeinen, trotz aller Verbesserungen und Abstraktionen, die über HTTP/1.x hinzugefügt wurden, sind praktisch keine Änderungen in den von Entwicklern verwendeten APIs notwendig, um HTTP/2 über HTTP/1.x zu nutzen. Wenn HTTP/2 sowohl im Browser als auch im Server verfügbar ist, wird es automatisch aktiviert und genutzt.
Pseudo-Header
Eine bemerkenswerte Änderung der Nachrichten in HTTP/2 ist die Verwendung von Pseudo-Headern.
Während HTTP/1.x die Nachrichtenstartzeile nutzte, verwendet HTTP/2 spezielle Pseudo-Header-Felder, die mit : beginnen.
In Anfragen gibt es folgende Pseudo-Header:
:method- Die HTTP-Methode.:scheme- Der Schemas-Teil der Ziel-URI, der oft HTTP(S) ist.:authority- Der Autoritäts-Teil der Ziel-URI.:path- Der Pfad- und Abfrageteil der Ziel-URI.
In Antworten gibt es nur einen Pseudo-Header, und das ist der :status, der den Code der Antwort bereitstellt.
Wir können eine HTTP/2-Anfrage mit nghttp erstellen, um example.com abzurufen, wodurch die Anfrage in einer formatierten Weise ausgedruckt wird, die leichter lesbar ist.
Sie können die Anfrage mit diesem Befehl erstellen, wobei die Option -n die heruntergeladenen Daten verwirft und -v für "verbose" Ausgabe ist, wobei Empfang und Übertragung von Frames angezeigt werden:
nghttp -nv https://www.example.com
Wenn Sie die Ausgabe durchsehen, sehen Sie das Timing für jeden übertragenen und empfangenen Frame:
[ 0.123] <send|recv> <frame-type> <frame-details>
Wir müssen nicht allzu sehr auf diese Ausgabe eingehen, aber achten Sie auf den HEADERS-Frame im Format [ 0.123] send HEADERS frame ....
In den Zeilen nach der Header-Übertragung werden Sie die folgenden Zeilen sehen:
[ 0.447] send HEADERS frame ...
...
:method: GET
:path: /
:scheme: https
:authority: www.example.com
accept: */*
accept-encoding: gzip, deflate
user-agent: nghttp2/1.61.0
Dies sollte Ihnen vertraut vorkommen, wenn Sie bereits mit HTTP/1.x arbeiten und die in dem früheren Abschnitt dieses Leitfadens behandelten Konzepte immer noch gelten.
Dies ist der binäre Rahmen mit der GET-Anfrage für example.com, konvertiert in eine lesbare Form von nghttp.
Wenn Sie weiter unten in der Ausgabe des Befehls schauen, werden Sie den :status Pseudo-Header in einem der vom Server empfangenen Streams sehen:
[ 0.433] recv (stream_id=13) :status: 200
[ 0.433] recv (stream_id=13) content-encoding: gzip
[ 0.433] recv (stream_id=13) age: 112721
[ 0.433] recv (stream_id=13) cache-control: max-age=604800
[ 0.433] recv (stream_id=13) content-type: text/html; charset=UTF-8
[ 0.433] recv (stream_id=13) date: Fri, 13 Sep 2024 12:56:07 GMT
[ 0.433] recv (stream_id=13) etag: "3147526947+gzip"
...
Und wenn Sie das Timing und die Stream-ID aus dieser Nachricht entfernen, sollte es noch vertrauter sein:
:status: 200
content-encoding: gzip
age: 112721
Weiter in Nachrichtenrahmen, Stream-IDs und wie die Verbindung verwaltet wird einzutauchen, liegt außerhalb des Rahmens dieses Leitfadens, aber um HTTP/2-Nachrichten zu verstehen und zu debuggen, sollten Sie mit dem Wissen und den Werkzeugen, die in diesem Artikel erwähnt werden, gut ausgestattet sein.
Fazit
Dieser Leitfaden gibt einen allgemeinen Überblick über die Anatomie von HTTP-Nachrichten, wobei das HTTP/1.1-Format zur Veranschaulichung verwendet wird. Wir haben auch die HTTP/2 Nachrichtenrahmung untersucht, die eine Schicht zwischen dem HTTP/1.x-Syntax und dem zugrunde liegenden Transportprotokoll einführt, ohne die HTTP-Semantik grundlegend zu ändern. HTTP/2 wurde eingeführt, um die Head-of-Line Blocking Probleme zu lösen, die in HTTP/1.x vorhanden sind, indem Multiplexing von Anfragen ermöglicht wird.
Ein Problem, das in HTTP/2 bestehen bleibt, ist, dass obwohl Head-of-Line Blocking auf Protokollebene behoben wurde, es immer noch eine Leistungsengpässe durch Head-of-Line Blocking innerhalb von TCP (auf der Transportschicht) gibt. HTTP/3 befasst sich mit dieser Einschränkung, indem es QUIC verwendet, ein Protokoll, das auf UDP basiert, anstatt TCP. Diese Änderung verbessert die Leistung, verkürzt die Verbindungsaufbauzeit und erhöht die Stabilität auf beeinträchtigten oder unzuverlässigen Netzwerken. HTTP/3 behält die gleichen Kern-HTTP-Semantiken bei, sodass Funktionen wie Anfragemethoden, Statuscodes und Header über alle drei Haupt-HTTP-Versionen hinweg konsistent bleiben.
Wenn Sie die Semantik von HTTP/1.1 verstehen, haben Sie bereits eine solide Grundlage, um HTTP/2 und HTTP/3 zu erfassen. Der Hauptunterschied liegt darin, wie diese Semantiken auf der Transporteebene implementiert werden. Mit den Beispielen und Konzepten in diesem Leitfaden sollten Sie sich nun gut gerüstet fühlen, um mit HTTP zu arbeiten und die Bedeutung von Nachrichten zu verstehen, sowie wie Anwendungen HTTP nutzen, um Daten zu senden und zu empfangen.
Siehe auch
- Evolution von HTTP
- Protokoll-Upgrade-Mechanismus
- Glossarbegriffe: