Inhaltsaushandlung
Im HTTP ist die Inhaltsaushandlung der Mechanismus, der verwendet wird, um verschiedene Darstellungen einer Ressource unter derselben URI bereitzustellen. Dies hilft dem Benutzeragenten, die am besten geeignete Darstellung für den Benutzer zu spezifizieren (zum Beispiel, welche Dokumentsprache, welches Bildformat oder welche Inhaltskodierung).
Hinweis:
Sie finden einige Nachteile der HTTP-Inhaltsaushandlung auf einer Wiki-Seite von WHATWG. HTML bietet Alternativen zur Inhaltsaushandlung über beispielsweise das <source>-Element.
Prinzipien der Inhaltsaushandlung
Ein spezifisches Dokument wird als Ressource bezeichnet. Wenn ein Client eine Ressource anfordern möchte, tut er dies über eine URL. Der Server verwendet diese URL, um eine der verfügbaren Varianten auszuwählen – jede Variante wird als Darstellung bezeichnet – und gibt eine spezifische Darstellung an den Client zurück. Sowohl die gesamte Ressource als auch jede der Darstellungen hat eine spezifische URL. Inhaltsaushandlung bestimmt, wie eine spezifische Darstellung ausgewählt wird, wenn die Ressource aufgerufen wird. Es gibt mehrere Möglichkeiten der Aushandlung zwischen dem Client und dem Server.
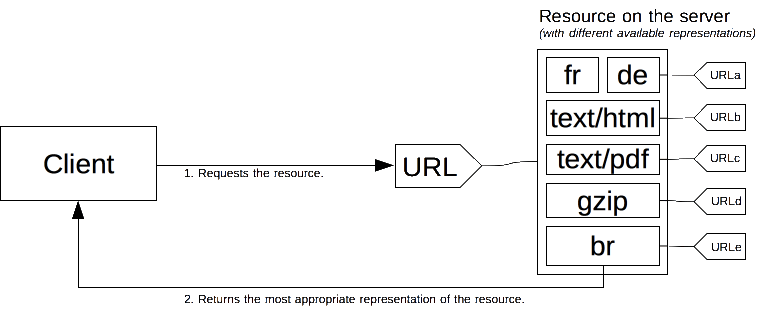
Die am besten geeignete Darstellung wird über einen der beiden Mechanismen identifiziert:
- Spezifische HTTP-Header vom Client (servergesteuerte Aushandlung oder proaktive Aushandlung), was die Standardmethode zum Aushandeln einer bestimmten Art von Ressource ist.
- Die
300(Mehrere Auswahlmöglichkeiten) oder406(Nicht akzeptabel),415(Nicht unterstützter Medientyp) HTTP-Antwortcodes vom Server (agentengesteuerte Aushandlung oder reaktive Aushandlung), die als Rückfallmechanismen verwendet werden.
Im Laufe der Jahre wurden andere Vorschläge zur Inhaltsaushandlung wie die transparente Inhaltsaushandlung und der Alternates-Header vorgeschlagen. Sie konnten sich nicht durchsetzen und wurden aufgegeben.
Servergesteuerte Inhaltsaushandlung
Bei der servergesteuerten Inhaltsaushandlung, oder proaktiven Inhaltsaushandlung, sendet der Browser (oder ein anderer Benutzeragent) mehrere HTTP-Header zusammen mit der URL. Diese Header beschreiben die bevorzugte Auswahl des Benutzers. Der Server verwendet sie als Hinweise und ein internes Algorithmus wählt den besten Inhalt aus, um ihn dem Client zu liefern. Wenn der Server keine geeignete Ressource bereitstellen kann, kann er mit 406 (Nicht akzeptabel) oder 415 (Nicht unterstützter Medientyp) antworten und Header für die Medientypen setzen, die er unterstützt (z.B. mit dem Accept-Post oder Accept-Patch für POST- und PATCH-Anfragen). Der Algorithmus ist serverspezifisch und nicht im Standard definiert. Siehe den Apache-Aushandlungsalgorithmus.
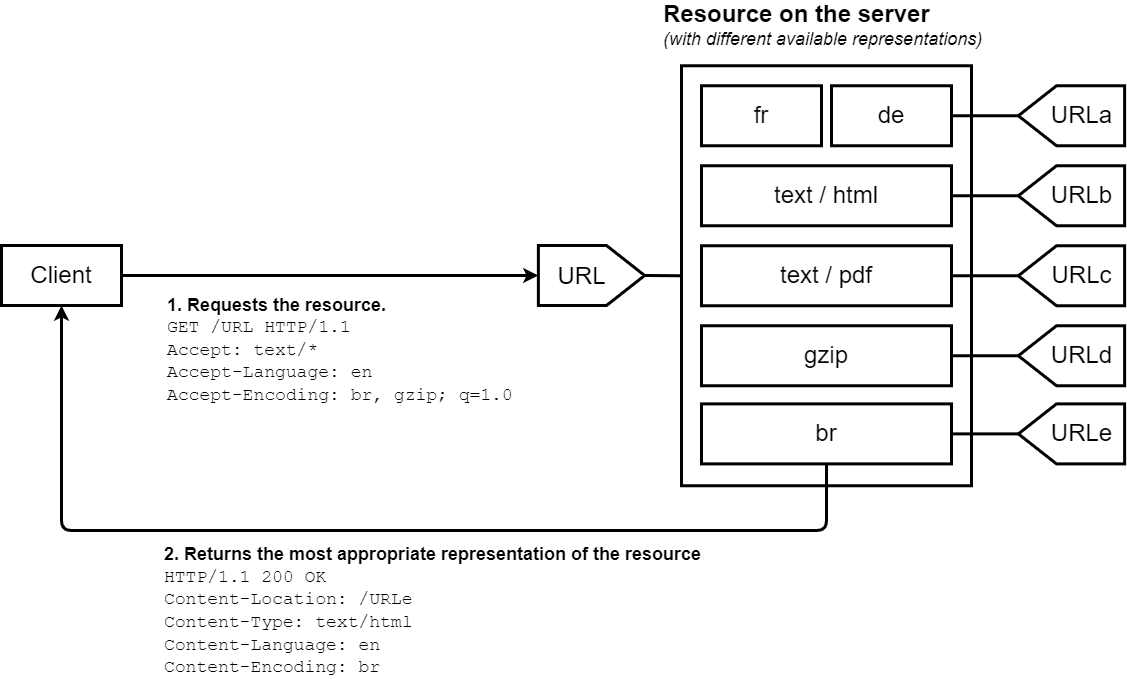
Der HTTP/1.1-Standard definiert eine Liste der Standard-Header, die die servergesteuerte Aushandlung starten (wie Accept, Accept-Encoding und Accept-Language). Obwohl User-Agent nicht in dieser Liste ist, wird es manchmal auch verwendet, um eine spezifische Darstellung der angeforderten Ressource zu senden. Dies wird jedoch nicht immer als gute Praxis angesehen. Der Server verwendet den Vary-Header, um anzuzeigen, welche Header er tatsächlich für die Inhaltsaushandlung verwendet hat (oder genauer gesagt die zugehörigen Anfrageheader), damit Caches optimal arbeiten können.
Zusätzlich zu diesen gibt es einen experimentellen Vorschlag, der mehr Header zur Liste der verfügbaren Header hinzufügt, genannt Client-Hinweise. Client-Hinweise geben bekannt, auf welcher Art von Gerät der Benutzeragent läuft (zum Beispiel ein Desktop-Computer oder ein mobiles Gerät).
Obwohl die servergesteuerte Inhaltsaushandlung die häufigste Methode ist, um sich auf eine spezifische Darstellung einer Ressource zu einigen, gibt es einige Nachteile:
- Der Server hat kein vollständiges Wissen über den Browser. Selbst mit der Client-Hints-Erweiterung hat er kein vollständiges Wissen über die Fähigkeiten des Browsers. Anders als bei der reaktiven Inhaltsaushandlung, bei der der Client die Wahl trifft, ist die Wahl des Servers immer etwas willkürlich.
- Die Informationen vom Client sind recht umfangreich (HTTP/2-Header-Komprimierung mildert dieses Problem) und stellen ein Datenschutzrisiko dar (HTTP-Fingerprinting).
- Da mehrere Darstellungen einer Ressource gesendet werden, sind gemeinsame Caches weniger effizient und Serverimplementierungen sind komplexer.
Der Accept-Header
Der Accept-Header listet die MIME-Typen der Medienressourcen auf, die der Agent verarbeiten kann. Dies ist eine durch Kommas getrennte Liste von MIME-Typen, die jeweils mit einem Qualitätsfaktor kombiniert sind, einem Parameter, der das relative Ausmaß der Bevorzugung zwischen den verschiedenen MIME-Typen angibt.
Der Accept-Header wird vom Browser oder einem anderen Benutzeragenten definiert und kann je nach Kontext variieren. Zum Beispiel beim Abrufen einer HTML-Seite oder eines Bildes, eines Videos oder eines Skripts. Er ist anders, wenn ein Dokument in der Adressleiste eingegeben oder ein Element über ein <img>, <video> oder <audio> Element verlinkt wird. Browser sind frei, den Wert des Headers zu verwenden, den sie für am besten geeignet halten; eine umfassende Liste der Standardwerte für gängige Browser ist verfügbar.
Der Accept-CH-Header
Hinweis: Dies ist Teil einer experimentellen Technologie namens Client-Hints. Erste Unterstützung kommt in Chrome 46 oder später. Der Device-Memory-Wert ist in Chrome 61 oder später enthalten.
Der experimentelle Accept-CH listet Konfigurationsdaten auf, die der Server verwenden kann, um eine geeignete Antwort auszuwählen. Gültige Werte sind:
| Wert | Bedeutung |
|---|---|
Device-Memory |
Gibt die ungefähre Menge an Geräte-RAM an. Dieser Wert ist eine Annäherung, die durch Runden auf die nächste Potenz von 2 und Teilen dieser Zahl durch 1024 gegeben ist. Zum Beispiel werden 512 Megabyte als 0.5 angegeben. |
Viewport-Width |
Gibt die Layout-Viewportbreite in CSS-Pixeln an. |
Width |
Gibt die Ressourcenbreite in physischen Pixeln an (in anderen Worten die intrinsische Größe eines Bildes). |
Der Accept-Encoding-Header
Der Accept-Encoding-Header definiert die akzeptablen Inhaltkodierungen (unterstützte Komprimierungen). Der Wert ist eine q-Faktor-Liste (z.B. br, gzip;q=0.8), die die Priorität der Kodierungswerte angibt. Der Standardwert identity hat die niedrigste Priorität (sofern nicht anders angegeben).
Das Komprimieren von HTTP-Nachrichten ist eine der wichtigsten Methoden, um die Leistung einer Website zu verbessern. Es verkleinert die Größe der übertragenen Daten und nutzt die verfügbare Bandbreite optimal. Browser senden diesen Header immer und der Server sollte so konfiguriert sein, dass er Komprimierung verwendet.
Der Accept-Language-Header
Der Accept-Language-Header wird verwendet, um die Sprachpräferenz des Benutzers anzuzeigen. Es ist eine Liste von Werten mit Qualitätsfaktoren (z.B. de, en;q=0.7). Ein Standardwert ist häufig entsprechend der Sprache der grafischen Schnittstelle des Benutzeragenten eingestellt, aber die meisten Browser erlauben es, unterschiedliche Sprachpräferenzen festzulegen.
Aufgrund des konfigurationsbasierten Entropie Anstiegs kann ein modifizierter Wert verwendet werden, um den Benutzer zu fingerprinten. Es wird nicht empfohlen, diesen Wert zu ändern, und eine Website kann nicht darauf vertrauen, dass dieser Wert die tatsächliche Absicht des Benutzers widerspiegelt. Es ist am besten, wenn Site-Designer die Spracherkennung über diesen Header vermeiden, da dies zu einer schlechten Benutzererfahrung führen kann.
- Sie sollten immer eine Möglichkeit bieten, die serverseitig gewählte Sprache zu überschreiben, z.B. durch ein Sprachmenü auf der Seite. Die meisten Benutzeragenten bieten einen Standardwert für den
Accept-Language-Header, der an die Benutzeroberflächensprache angepasst ist. Endbenutzer ändern ihn oft nicht, weil sie entweder nicht wissen, wie es geht, oder weil sie es aufgrund ihrer Computerumgebung nicht können. - Sobald ein Benutzer die serverseitig gewählte Sprache überschrieben hat, sollte eine Website keine Spracherkennung mehr verwenden und bei der explizit gewählten Sprache bleiben. Mit anderen Worten, nur Einstiegsseiten für eine Website sollten diesen Header verwenden, um die richtige Sprache auszuwählen.
Der User-Agent-Header
Hinweis: Obwohl es legitime Verwendungszwecke für diesen Header zur Auswahl von Inhalt gibt, wird es als schlechte Praxis angesehen, sich darauf zu verlassen, um zu definieren, welche Funktionen der Benutzeragent unterstützt.
Der User-Agent-Header identifiziert den Browser, der die Anfrage sendet. Diese Zeichenkette kann eine durch Leerzeichen getrennte Liste von Produkt-Token und Kommentare enthalten.
Ein Produkt-Token ist ein Name, gefolgt von einem Schrägstrich und einer Versionsnummer, wie Firefox/4.0.1. Der Benutzeragent kann so viele davon hinzufügen, wie er möchte. Ein Kommentar ist eine optionale Zeichenkette, die durch Klammern abgegrenzt ist. Die in einem Kommentar bereitgestellten Informationen sind nicht standardisiert, obwohl einige Browser mehrere Token hinzufügen, die durch ; getrennt sind.
Der Vary-Antwortheader
Im Gegensatz zu den vorherigen Accept-*-Headern, die vom Client gesendet werden, wird der Vary-HTTP-Header vom Webserver in seiner Antwort gesendet. Er gibt die Liste der Header an, die der Server während der servergesteuerten Inhaltsaushandlungsphase verwendet. Der Vary-Header ist erforderlich, um den Cache über die Entscheidungskriterien zu informieren, damit er sie reproduzieren kann. Dies ermöglicht es dem Cache, funktional zu sein und sicherzustellen, dass dem Benutzer der richtige Inhalt geliefert wird.
Der spezielle Wert * bedeutet, dass die servergesteuerte Inhaltsaushandlung auch Informationen verwendet, die nicht in einem Header übertragen werden, um den geeigneten Inhalt auszuwählen.
Der Vary-Header wurde in Version 1.1 von HTTP hinzugefügt und ermöglicht es den Caches, ordnungsgemäß zu funktionieren. Um mit der servergesteuerten Inhaltsaushandlung zu arbeiten, muss ein Cache wissen, welche Kriterien der Server verwendet hat, um den übertragenen Inhalt auszuwählen. Auf diese Weise kann der Cache den Algorithmus wiederholen und direkt akzeptablen Inhalt bereitstellen, ohne weitere Anfragen an den Server. Offensichtlich verhindert der Platzhalter * das Caching, da der Cache nicht wissen kann, welches Element dahinterliegt. Weitere Informationen finden Sie unter HTTP-Caching > Variierende Antworten.
Agentengesteuerte Aushandlung
Die servergesteuerte Aushandlung weist einige Nachteile auf: sie skaliert nicht gut. Ein Header pro Funktion wird in der Aushandlung verwendet. Wenn Sie Bildschirmgröße, Auflösung oder andere Dimensionen verwenden möchten, müssen Sie einen neuen HTTP-Header erstellen. Die Header müssen dann mit jeder Anfrage gesendet werden. Das ist kein Problem, wenn nur wenige Header vorhanden sind, aber wenn die Anzahl der Header zunimmt, könnte die Nachrichtengröße irgendwann die Leistung beeinträchtigen. Je genauer die Header gesendet werden, desto mehr Entropie wird gesendet, was mehr HTTP-Fingerprinting und entsprechende Datenschutzbedenken ermöglicht.
HTTP ermöglicht eine andere Aushandlungsart: agentengesteuerte Aushandlung oder reaktive Aushandlung. In diesem Fall sendet der Server eine Seite zurück, die Links zu den verfügbaren alternativen Ressourcen enthält, wenn er mit einer mehrdeutigen Anfrage konfrontiert wird. Dem Benutzer werden die Ressourcen präsentiert und er wählt diejenige aus, die er verwenden möchte.
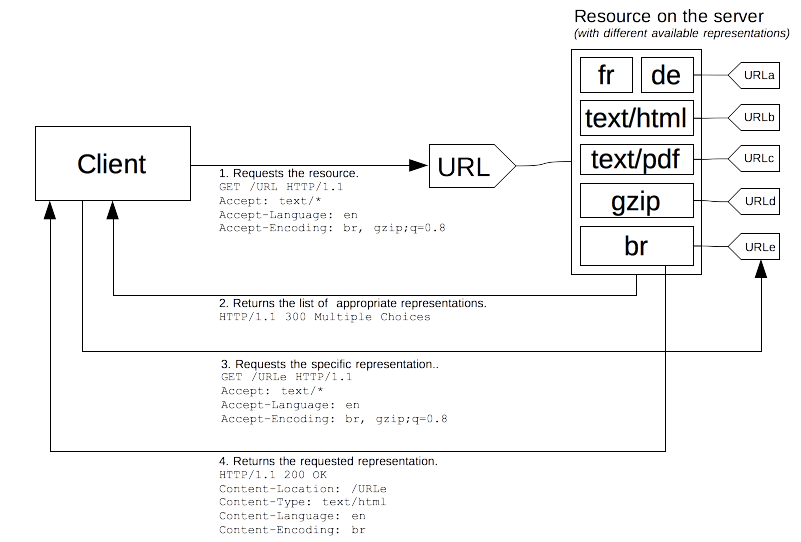
Leider spezifiziert der HTTP-Standard nicht das Format der Seite zur Auswahl zwischen den verfügbaren Ressourcen, was den Prozess daran hindert, automatisiert zu werden. Neben dem Rückfallen auf die servergesteuerte Aushandlung wird diese Methode fast immer mit Skripten verwendet, insbesondere mit JavaScript-Weiterleitung: nachdem die Aushandlungskriterien überprüft wurden, führt das Skript die Weiterleitung durch. Ein weiteres Problem ist, dass eine weitere Anfrage erforderlich ist, um die tatsächliche Ressource abzurufen, was die Verfügbarkeit der Ressource für den Benutzer verlangsamt.