HTML、CSS 和 DOM 中的空白符是如何处理的
在 DOM 中,空白符的存在会导致布局问题,并使内容树的操作变得困难,这取决于它的位置。这篇文章探讨了什么时候会出现困难,并研究了如何缓解由此产生的问题。
什么是空白符?
空白符是指任何仅由空格、制表符或换行符(准确地说,是 CRLF 序列、回车或换行)组成的文本串。这些字符允许你以一种使你自己和其他人容易阅读的方式来格式化你的代码。事实上,我们的大部分源代码都充满了这些空白字符,我们只倾向于在生产构建步骤中去掉它,以减少代码下载量。
HTML 会大幅度忽略空白符吗?
就 HTML 而言,空白符基本上是被忽略的——单词之间的空白被视为一个字符,而元素的开始和结束以及元素之外的空白则被忽略。以下面这个最小的示例为例:
<!DOCTYPE html>
<h1> Hello World! </h1>
这段源代码在 DOCTYPE 后面有几个换行符,在 <h1> 元素前后和里面有很多空格字符,但浏览器似乎根本不在乎,只是显示“Hello World!”,好像这些字符根本不存在:
这是为了使空白字符不影响你的页面布局。在元素周围和内部创造空间是 CSS 的工作。
空白符发生了什么?
然而,它们不会就这样消失。
任何在原始文档中的 HTML 元素之外的空白字符都会在 DOM 中表现出来。这在内部是需要的,以便编辑器可以保留文档的格式。这意味着:
- 会有一些文本节点只包含空白,而且
- 有些文本节点会在开头或结尾有空白。
以下列文档为例:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
其 DOM 树类似于这样:

在 DOM 中保留空白字符在很多方面都是有用的,但在某些地方,这使得某些布局更难实现,并给那些想在 DOM 中迭代节点的开发者带来了问题。我们将在后面讨论这些问题,以及一些解决方案。
CSS 如何处理空白符?
大多数空白字符会被忽略,但不是所有的都会被忽略。在前面的示例中,“Hello”和“World!”之间的一个空格在浏览器中渲染时仍然存在。浏览器引擎中有一些规则来决定哪些空白字符是有用的,哪些是没用的——这些规则至少在 CSS 文本模块第 3 级中作了部分说明,特别是关于 CSS white-space 属性和空白符处理细节的部分,但我们也在下面提供一个更简单的解释。
示例
让我们看看其他示例,为了使它看起来更简单,我们添加了一个注释,将所有的空格显示为“◦”,所有的制表符显示为“⇥”,所有的换行符显示为“⏎”:
这个示例
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
会在浏览器中像这样渲染:
解释
<h1> 元素只包含行内元素,实际上包含:
- 一个文本节点(包含一些空格,单词“Hello”和一些制表符)。
- 一个行内元素(
<span>,包含一个空格和一个单词“World!”)。 - 另外一个文本节点(只包含制表符和空格)。
正因为如此,它建立了所谓的行内格式化上下文。这是浏览器引擎可能使用的布局渲染上下文之一。
在这个上下文中,空白符的处理可以总结如下:
-
首先,换行前后的所有空格和制表符都会被忽略,所以,如果我们拿之前的示例标记:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>然后应用这条规则,会得到:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
然后,所有制表符视作空格字符,所以这个示例会变为:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>◦◦◦</h1> -
然后,换行符被转化为空格符:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1> -
之后,任何紧跟在另一个空格之后的空格(甚至跨越两个独立的行内元素)都会被忽略,所以我们会得到:
html<h1>◦Hello◦<span>World!</span></h1> -
最后,元素开头和结尾的空格序列被删除,所以我们最终得到了:
html<h1>Hello◦<span>World!</span></h1>
这就是为什么人们在访问网页时,会看到“Hello World!”这句话很好地写在页面的顶部,而不是一个奇怪的缩进的“Hello”,但在下面一行有一个更奇怪的缩进的“World!”。
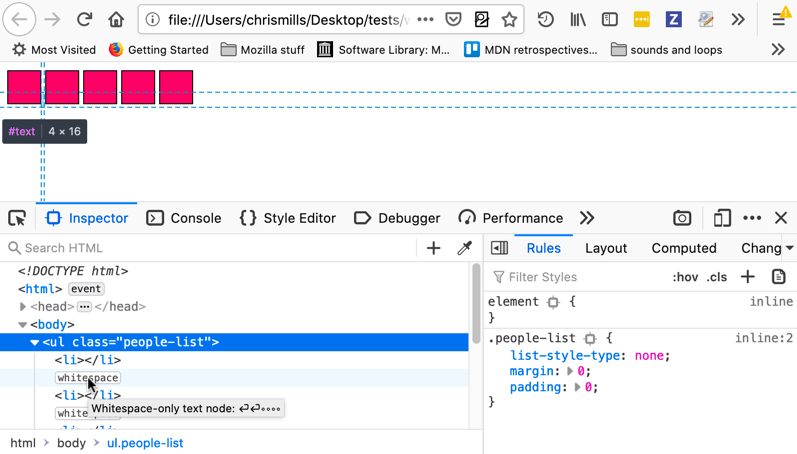
备注: 从版本 52 开始,Firefox 开发者工具支持高亮文本节点,使得观察包含节点中包含的空白字符变得更加容易。纯的空白符节点会有一个“whitespace”标记。
在区块格式化上下文的空白符
上面我们只是看了包含行内元素的元素,以及行内格式化上下文。如果一个元素至少包含一个块元素,那么它就会建立所谓的区块格式化上下文。
这种情况下,空白符的处理方式非常不同。
示例
让我们看看一个示例来解释发生了什么。我们已经像以前一样标记了空白字符。
我们有三个文本节点,一个在第一个 <div> 之前,一个在 2 个 <div> 之间,还有一个在第二个 <div> 之后。
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>◦◦Hello◦◦</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
它会像这样渲染:
解释
我们可以将这里的空白符处理方式总结如下(不同的浏览器在具体行为上可能有一些细微的差别,但这基本上是可行的):
-
因为我们在块格式化上下文内,所有部分必须是一个块,所以我们的 3 个文本节点也会组成各自的“块”,就像这 2 个
<div>一样。块占据了可用的全部宽度,并且相互堆叠,这意味着,从上面的示例开始:html<body>⏎ ⇥<div>◦◦Hello◦◦</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>我们会得到一个由多个“块”组成的布局:
html<block>⏎⇥</block> <block>◦◦Hello◦◦</block> <block>⏎◦◦◦</block> <block>◦◦World!◦◦</block> <block>◦◦⏎</block> -
然后通过对这些块应用行内格式化背景下的空白处理规则来进一步简化:
html<block></block> <block>Hello</block> <block></block> <block>World!</block> <block></block> -
我们现在拥有的 3 个空块不会在最终的布局中占据任何空间,因为它们不包含任何东西,所以我们最终将只有 2 个块在页面中占据空间。人们在浏览网页时,会看到“Hello”和“World!”这两个词分别出现在两行上,就像你所期望的那样,两个
<div>被排列出来。浏览器引擎基本上忽略了在源代码中添加的所有空白符处。
在行内和行内块元素之间的空格
让我们继续看看由于空白符可能产生的几个问题,以及如何解决这些问题。首先,我们来看看在行内和行内块元素之间的空格会发生什么。事实上,我们在第一个示例中已经看到了这一点,当时我们描述了在行内格式化背景下是如何处理空白的。
我们说过,存在可以忽略大多数字符,但分词的字符仍然存在的规则。当你只是处理像 <p> 这样只包含 <em>、<strong>、<span> 等行级元素的块级元素时,通常没有必要关心这个问题,因为布局中的额外空白符有助于分隔句子中的单词。
当你开始使用行内块元素时,情况会变得更加有趣。这些元素的行为就像外面的行内元素和里面的块,通常用于显示更复杂的 UI,而不仅仅是文本,并排在同一行,例如导航菜单项。
因为它们是块,许多人期望它们会有这样的行为,但实际上它们并没有。如果相邻的行内元素之间有格式化的空白,这将导致布局中的空白,就像文本中的单词之间的空白一样。
示例
考虑这个示例,当然,我们像之前的示例一样包含了显示出所有空白字符的 HTML 注释。
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #f06;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
这个示例将渲染为这样:
根据使用情况(是头像列表,还是水平导航按钮?),你可能不希望块之间包含空隙。你可能希望元素的两边彼此平齐,并且能够自己控制任何间距。
Firefox 开发者工具 HTML 检查器将突出显示文本节点,并准确显示这些元素所占用的面积。如果你想知道是什么原因造成的问题,并可能认为你在那里有一些额外的内边距或其他东西,那就很有用了!
解决方案
有一些方法来解决这个问题:
使用弹性盒子来创建项目的水平列表,而不是尝试 inline-block 解决方案。这可以为你处理一切,而且绝对是首选的解决方案:
ul {
list-style-type: none;
margin: 0;
padding: 0;
display: flex;
}
如果你确实需要依赖于 inline-block,你可以将列表的 font-size 设置为 0。这只有在你的区块不是用 em 确定大小(em 基于 font-size,所以区块大小最终也会是 0)的情况下才有效。rem 在这里是更好的选择:
ul {
font-size: 0;
/* … */
}
li {
display: inline-block;
width: 2rem;
height: 2rem;
/* … */
}
或者,你可以在列表项中设置负内边距:
li {
display: inline-block;
width: 2rem;
height: 2rem;
margin-right: -0.25rem;
}
你也可以通过把你的列表项放在源文件的同一行来解决这个问题,这将导致首先不创建空白节点:
<li></li><li></li><li></li><li></li><li></li>
DOM 遍历与空白符
当试图在 JavaScript 中进行 DOM 操作时,你也可能因为空白节点而遇到问题。例如,如果你有一个对父节点的引用,并想用 Node.firstChild 来影响它的第一个元素子节点,如果在打开的父标签之后有一个意外的空白节点,你将不会得到你所期望的结果。文本节点会被选中,而不是你想影响的元素。
再比如,如果你有一个特定的元素子集,你想根据它们是否为空(没有子节点)来做一些事情,你可以使用类似 Node.hasChildNodes() 的东西来检查每个元素是否为空,但同样,如果任何目标元素包含文本节点,你可能会得到错误的结果。
空白符辅助函数
以下的 JavaScript 代码定义了许多函数,能够让你在处理 DOM 中的空白符时轻松点:
/**
* 以下所谓的“空白符”代表:
* "\t" TAB \u0009(制表符)
* "\n" LF \u000A(换行符)
* "\r" CR \u000D(回车符)
* " " SPC \u0020(真正的空格符)
*
* 不使用 JavaScript 的“\s”,因为它包含不断行空白字符等其他字符。
*/
/**
* 测知某节点的文字内容是否全为空白。
*
* @param nod |CharacterData| 类的节点(如 |Text|、|Comment| 或 |CDATASection|)。
* @return 若 |nod| 的文字内容全为空白则返回 true,否则返回 false。
*/
function is_all_ws(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* 测知是否应在遍历时略过某节点。
*
* @param nod DOM1 |Node| 对象
* @return 若 |Text| 节点内仅有空白符或为 |Comment| 节点时,传回 true,
* 否则返回 false。
*/
function is_ignorable(nod) {
return (
nod.nodeType === 8 || // 注释节点
(nod.nodeType === 3 && is_all_ws(nod))
); // 所有字符都是空白字符的文本节点
}
/**
* 此为会跳过空白符节点及注释节点的 |previousSibling| 函数
*(|previousSibling| 是 DOM 节点的特性值,为该节点的前一个节点。)
*
* @param sib 节点引用。
* @return 有两种可能:
* 1) |sib| 的最近前一个“不可忽略节点”,由 |is_ignorable| 决定。或
* 2) 若该节点前无任何此类节点,则返回 null。
*/
function node_before(sib) {
while ((sib = sib.previousSibling)) {
if (!is_ignorable(sib)) return sib;
}
return null;
}
/**
* 此为会跳过空白符节点及注释节点的 |nextSibling| 函数
*
* @param sib 节点引用。
* @return 有两种可能:
* 1) |sib| 的最近后一个“不可忽略节点”,由 |is_ignorable| 决定。或
* 2) 若该节点后无任何此类节点,则返回 null。
*/
function node_after(sib) {
while ((sib = sib.nextSibling)) {
if (!is_ignorable(sib)) {
return sib;
}
}
return null;
}
/**
* 此为会跳过空白符节点及注释节点的 |lastChild| 函数
*(|lastChild| 是 DOM 节点的特性值,为该节点之中最后一个子节点。)
*
* @param par 节点引用。
* @return 有两种可能:
* 1) |par| 中最后一个“不可忽略的子节点”,由 |is_ignorable| 决定。或
* 2) 若该节点中无任何此类子节点,则返回 null。
*/
function last_child(par) {
let res = par.lastChild;
while (res) {
if (!is_ignorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* 此为会跳过空白符节点及注释节点的 |firstChild| 函数
*
* @param par 节点引用。
* @传回值 有两种可能:
* 1) |par| 中第一个“不可忽略的子节点”,由 |is_ignorable| 决定。或
* 2) 若该节点中无任何此类子节点,则返回 null。
*/
function first_child(par) {
let res = par.firstChild;
while (res) {
if (!is_ignorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* 此为返回不包含文字节点的首尾所有空白符、
* 并将两个以上的空白符缩减为一个的 |data| 函数。
*(|data| 是 DOM 文字节点的特性值,为该文字节点中的文本。)
*
* @param txt 欲返回其中数据的文字节点
* @return 文字节点的内容,其中空白符已依前述方式处理。
*/
function data_of(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
示例
下面的代码演示了上面这些工具函数的使用方法。具体操作是,遍历一个子节点全部为元素节点的元素,找到所包含的第一个节点为一个文本内容为“This is the third paragraph”的文本节点的那个子元素,并修改该子元素的 class 属性及其第一个文本节点的文字内容。
let cur = first_child(document.getElementById("test"));
while (cur) {
if (data_of(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = node_after(cur);
}