Uso de la Web Speech API
La API Web Speech API proporciona dos funcionalidades distintas — reconocimiento de voz, y síntesis de voz (también conocido como texto a voz o tts) — lo que nos ofrece nuevas e interesantes posibilidades para accesibilidad y otros mecanismos. Este artículo ofrece una breve introducción en las dos áreas, así como unas demos.
Reconocimiento de voz
El reconocimiento de voz implica recibir voz a través del micrófono de un dispositivo, luego es verificado por un servicio de reconocimiento de voz contra una lista de palabras o frases 'grammar' (esta lista básicamente es el vocabulario a reconocer en una app particular). Cuando se reconoce con éxito una palabra o frase, esta se devuelve como una cadena de texto y así poder iniciar otras acciones.
La API Web Speech tiene una interfaz principal de control para el - SpeechRecognition -, además de una serie de interfaces estrechamente relacionadas para representar la gramática, los resultados, etc. Normalmente, el sistema de reconocimiento de voz predeterminado que dispone el dispositivo se utilizará para el reconocimiento de voz: la mayoría de los sistemas operativos modernos tienen un sistema de reconocimiento de voz para emitir comandos de voz. Piense en Dictado en macOS, Siri en iOS, Cortana en Windows 10, Android Speech, etc.
Nota: En algunos navegadores como Chrome, el uso del reconocimiento de voz implica el uso de un motor de reconocimiento basado en un servidor. Tu audio se envía a un servicio de reconocimiento web para ser procesado, por lo que no funcionará offline.
Demo
Para mostrar un uso sencillo del reconocimiento de voz Web, hemos escrito una demo llamada Speech color changer. Cuando se toca o hace click en la pantalla, se puede decir un color HTML, y el color de fondo de la aplicación cambiará a ese color.

Para ejecutar la demo, se puede clonar (o directamente descargar) el repositorio Github donde se encuentra, abrir el fichero index HTML en un navegador de escritorio compatible, o navegar a través del enlace live demo URL en un navegador de móvil compatible como Chrome.
Compatibilidad de navegadores
Actualmente, la compatibilidad de la Web Speech API para el reconocimiento de voz se limita a Chrome para escritorio y Android — Chrome tiene soporte desde la versión 33 pero con interfaces 'prefixed', por lo que se deben incluir ese tipo de interfaces 'prefixed', por ejemplo webkitSpeechRecognition.
HTML y CSS
El HTML y el CSS para esta app no son importantes. Solo tenemos un título, instrucciones en un párrafo, y un div dentro del cual visualizaremos los mensajes de diagnósticos.
<h1>Speech color changer</h1>
<p>Tap/click then say a color to change the background color of the app.</p>
<div>
<p class="output"><em>...diagnostic messages</em></p>
</div>
El CSS proporciona un estilo responsive muy simple para que se visualice bien en todos los dispositivos.
JavaScript
Miremos el JavaScript con un poco más de detalle.
Compatibilidad con Chrome
Como se ha mencionado anteriormente, Chrome actualmente admite el reconocimiento de voz con propiedades 'prefixed', por lo tanto, al principio de nuestro código incluiremos las siguientes líneas para usar los objetos que correspondan a Chrome, y así cualquier implementación en el futuro pueda admitir estas características sin ningún 'prefixed':
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
var SpeechGrammarList = SpeechGrammarList || webkitSpeechGrammarList;
var SpeechRecognitionEvent =
SpeechRecognitionEvent || webkitSpeechRecognitionEvent;
La gramática -grammar-
Las siguientes líneas de código definen la gramática que queremos que reconozca nuestra app. Se define una variable para contener nuestra gramática:
var colors = [ 'aqua' , 'azure' , 'beige', 'bisque', 'black', 'blue', 'brown', 'chocolate', 'coral' ... ];
var grammar = '#JSGF V1.0; grammar colors; public <color> = ' + colors.join(' | ') + ' ;'
El formato usado para 'grammar' es JSpeech Grammar Format (JSGF) — Se puede encontrar más sobre las especificaciones de este formato en el anterior enlace. Sin embargo y por ahora vamos a echarle un vistazo rápidamente:
- Las líneas se separan con punto y coma como en JavaScript.
- La primera línea —
#JSGF V1.0;— establece el formato y versión utilizados. Esto siempre se debe incluir primero. - La segunda línea indica el tipo de términos que queremos que se reconozcan.
publicdeclara que es una regla pública, la cadena entre los paréntesis angulares definen el nombre reconocido para éste término (color), y la lista de elementos que siguen al signo igual son los valores alternativos que se reconocerán y aceptaran como valores apropiados al término. Observar como cada elemento se separa con el carácter pipe ' | ' . - Se pueden definir tantos términos como se desee en líneas separadas siguiendo la estructura anterior, e incluir definiciones gramaticales complejas. Esta demostración básica la mantenemos lo más simple posible.
Conectando la gramática a nuestro reconocimiento de voz
Lo siguiente que tenemos que hacer es definir una instancia de reconocimiento de voz para el control en nuestra aplicación. Esto se hace usando el constructor SpeechRecognition(). También creamos una lista de gramática de voz para contener nuestra gramática usando el constructor SpeechGrammarList().
var recognition = new SpeechRecognition();
var speechRecognitionList = new SpeechGrammarList();
Añadimos nuestra grammar a la lista anterior usando el método SpeechGrammarList.addFromString(). Este método acepta como parámetro la cadena que queremos añadir, así como opcionalmente, un valor que especifique la importancia de esta gramática en relación a otras gramáticas disponibles en la lista (el rango del valor va desde 0 hasta 1 inclusive). La gramática agregada está disponible en la lista como una instancia del objeto SpeechGrammar.
speechRecognitionList.addFromString(grammar, 1);
Después añadimos la lista SpeechGrammarList a la instancia del reconocimiento de voz estableciéndola en la propiedad SpeechRecognition.grammars. También establecemos algunas otras propiedades a la instancia de reconocimiento antes de continuar:
SpeechRecognition.continuous: Controla si se capturan los resultados de forma continua (true), o solo un resultado cada vez que se inicia el reconocimiento (false).SpeechRecognition.lang: Establece el idioma del reconocimiento. Esto es una buena práctica y, por lo tanto, recomendable.SpeechRecognition.interimResults: Define si el sistema de reconocimiento de voz debe devolver resultados provisionales o solo resultados finales. Para nuestra demo es suficiente con los resultados finales.SpeechRecognition.maxAlternatives: Establece el número de posibles coincidencias alternativas que se deben devolver por resultado. Esto a veces puede ser útil, por ejemplo, si un resultado no está completamente claro y desea mostrar una lista de alternativas para que el usuario elija la correcta. Esta opción no es necesaria para la demo, por lo que solo especificamos una (la cual es la predeterminada).
recognition.grammars = speechRecognitionList;
recognition.continuous = false;
recognition.lang = "en-US";
recognition.interimResults = false;
recognition.maxAlternatives = 1;
Comenzando el reconocimiento de voz
Tomamos las referencias de la salida <div> y del elemento HTML (para que podamos enviar mensajes de diagnostico y actualizar el color de fondo de la aplicación más adelante), e implementamos un manejador onclick para que cuando se haga click o se toque la pantalla, se inicie el reconocimiento de voz. Esto se logra llamando al método SpeechRecognition.start(). El método forEach() se usa para visualizar indicadores de colores que muestran qué colores intenta decir.
var diagnostic = document.querySelector(".output");
var bg = document.querySelector("html");
var hints = document.querySelector(".hints");
var colorHTML = "";
colors.forEach(function (v, i, a) {
console.log(v, i);
colorHTML += '<span style="background-color:' + v + ';"> ' + v + " </span>";
});
hints.innerHTML =
"Tap/click then say a color to change the background color of the app. Try " +
colorHTML +
".";
document.body.onclick = function () {
recognition.start();
console.log("Ready to receive a color command.");
};
Recepción y manejo de resultados
Una vez que comienza el reconocimiento de voz, hay muchos manejadores de eventos que se pueden usar para recuperar los resultados, así como otros elementos de información adicional (ver SpeechRecognition event handlers list.) El más común que probablemente usarás es SpeechRecognition.onresult, el cual es lanzado cuando se recibe el resultado con éxito:
recognition.onresult = function (event) {
var color = event.results[0][0].transcript;
diagnostic.textContent = "Result received: " + color + ".";
bg.style.backgroundColor = color;
console.log("Confidence: " + event.results[0][0].confidence);
};
La tercera línea es un poco más compleja, así que vamos a explicarla paso a paso. La propiedad SpeechRecognitionEvent.results devuelve un objeto SpeechRecognitionResultList que contiene los objetos SpeechRecognitionResult. Tiene un getter para que pueda ser accesible como si fuera un array — así el primer [0] devuelve el SpeechRecognitionResult en la posición 0. Cada objeto SpeechRecognitionResult contiene objetos SpeechRecognitionAlternative que contienen palabras individuales reconocidas. Estos también tienen getters para que se puedan acceder a ellos como arrays — por lo tanto el segundo [0] devuelve SpeechRecognitionAlternative en la posición 0. Luego devolvemos su propiedad transcript para obtener una cadena que contenga el resultado individual reconocido como un string, estableciendo el color de fondo a ese color, e informando del color reconocido como un mensaje de diagnóstico en el IU.
También usamos el manejador SpeechRecognition.onspeechend para parar el servicio de reconocimiento de voz (usando SpeechRecognition.stop()) cuando se ha reconocido una sola palabra y se ha finalizado de hablar:
recognition.onspeechend = function () {
recognition.stop();
};
Manejo de errores y voz no reconocida
Los dos últimos manejadores son para controlar los casos donde no se reconoce ninguna de las palabras definidas en la gramática, o cuando ocurre un error. SpeechRecognition.onnomatch maneja el primer caso mencionado, pero tenga en cuenta que de momento no parece que se dispare correctamente; solo devuelve lo que ha reconocido:
recognition.onnomatch = function (event) {
diagnostic.textContent = "I didnt recognise that color.";
};
SpeechRecognition.onerror maneja los casos donde se ha producido en error en el reconocimiento — la propiedad SpeechRecognitionError.error contiene el error devuelto:
recognition.onerror = function (event) {
diagnostic.textContent = "Error occurred in recognition: " + event.error;
};
Síntesis de voz
La síntesis de voz (también conocida como texto a voz o tts) implica recibir contenido en forma de texto dentro de una aplicación y convertirla en voz a través del altavoz del dispositivo o de la conexión de salida del audio.
La Web Speech API tiene una interface principal controladora — SpeechSynthesis — además de una serie de interfaces estrechamente relacionadas para representar el texto que se va a sintetizar (conocido como dictados 'utterances'), voces que se usarán para los dictados, etc. De nuevo, la mayoría de sistemas operativos disponen de algún sistema de síntesis de voz que pueden serán usados por la API si están disponibles.
Demo
Para mostrar un uso sencillo de la síntesis de voz Web, tenemos la demo llamada Speak easy synthesis. Esta incluye un juego de controles de formulario para introducir texto a sintetizar, configurar el tono, velocidad de reproducción y la voz a usar cuando el texto sea pronunciado. Después de introducir el texto se puede presionar Enter/Return para escucharlo.
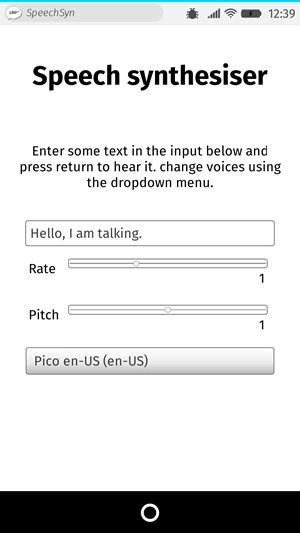
Para ejecutar la demo, se puede clonar (o directamente descargar) el repositorio Github donde se encuentra, abrir el fichero index HTML en un navegador de escritorio compatible, o navegar a través del enlace live demo URL en un navegador de móvil compatible como Chrome.
Compatibilidad de navegadores
El soporte para la síntesis de voz Web Speech API solo ha llegado a los navegadores más importantes y actualmente se limita a los siguientes:
- Firefox para escritorio y dispositivos móviles en Gecko 42+ (Windows)/44+, sin prefijos, y se puede activar configurando el flag
media.webspeech.synth.enabledatrueenabout:config. - Firefox OS 2.5+ lo soporta por defecto y sin ser necesario ningún permiso.
- Chrome para escritorio y Android tienen soporte desde la versión 33, sin prefijos.
HTML y CSS
El HTML y CSS de nuevo no son fundamentales, simplemente contiene un titulo, algunas instrucciones de uso y un formulario con algunos controles sencillos. El elemento <select> inicialmente está vacío pero se rellena con <option> mediante JavaScript (ver más adelante.)
<h1>Speech synthesiser</h1>
<p>
Enter some text in the input below and press return to hear it. change voices
using the dropdown menu.
</p>
<form>
<input type="text" class="txt" />
<div>
<label for="rate">Rate</label
><input type="range" min="0.5" max="2" value="1" step="0.1" id="rate" />
<div class="rate-value">1</div>
<div class="clearfix"></div>
</div>
<div>
<label for="pitch">Pitch</label
><input type="range" min="0" max="2" value="1" step="0.1" id="pitch" />
<div class="pitch-value">1</div>
<div class="clearfix"></div>
</div>
<select></select>
</form>
JavaScript
Analicemos el JavaScript usado en esta app.
Configurar variables
En primer lugar, capturamos las referencias de todos los elementos DOM involucrados en la IU, pero lo más importante es capturar una referencia a Window.speechSynthesis. Este es el punto de entrada a la API — devuelve una instancia a SpeechSynthesis, la interface controladora para la síntesis de voz en la web.
var synth = window.speechSynthesis;
var inputForm = document.querySelector("form");
var inputTxt = document.querySelector(".txt");
var voiceSelect = document.querySelector("select");
var pitch = document.querySelector("#pitch");
var pitchValue = document.querySelector(".pitch-value");
var rate = document.querySelector("#rate");
var rateValue = document.querySelector(".rate-value");
var voices = [];
Rellenar el elemento select
Para rellenar el elemento <select> con las diferentes opciones de voz del que dispone el dispositivo, hemos escrito la función populateVoiceList(). Primero invocamos SpeechSynthesis.getVoices(), que devuelve una lista de todas las voces disponibles representadas por objetos SpeechSynthesisVoice. Después recorremos esa lista — para cada voz creamos un elemento <option>, establecemos su contenido con el nombre de la voz (desde SpeechSynthesisVoice.name), y el lenguaje de la misma (desde SpeechSynthesisVoice.lang), y -- DEFAULT si la voz es la predeterminada para el motor de síntesis (verificando si SpeechSynthesisVoice.default devuelve true.)
Para cada opción también creamos atributos data-, conteniendo el nombre y lenguaje de la voz asociada, para que más tarde podamos usarlos fácilmente, y después añadimos las opciones 'option' como hijos del select.
function populateVoiceList() {
voices = synth.getVoices();
for (i = 0; i < voices.length; i++) {
var option = document.createElement("option");
option.textContent = voices[i].name + " (" + voices[i].lang + ")";
if (voices[i].default) {
option.textContent += " -- DEFAULT";
}
option.setAttribute("data-lang", voices[i].lang);
option.setAttribute("data-name", voices[i].name);
voiceSelect.appendChild(option);
}
}
Cuando vamos a ejecutar la función hacemos lo siguiente debido a que Firefox no soporta SpeechSynthesis.onvoiceschanged, y sólo devolverá una lista de voces cuando se ejecute SpeechSynthesis.getVoices(). Sin embargo con Chrome solo hay que esperar a que se active el evento antes de rellenar la lista, de ahí la siguiente parte de código.
populateVoiceList();
if (speechSynthesis.onvoiceschanged !== undefined) {
speechSynthesis.onvoiceschanged = populateVoiceList;
}
Reproduciendo el texto introducido
A continuación, creamos un manejador de eventos para comenzar a reproducir el texto introducido en el campo de texto. Usamos un manejador onsubmit en el formulario para que la acción ocurra cuando se presione Enter/Return. Primero creamos una nueva instancia de SpeechSynthesisUtterance() usando su constructor — a este se le pasa el valor de la entrada de texto como parámetro.
A continuación, debemos obtener la voz que queremos utilizar. Usamos la propiedad HTMLSelectElement selectedOptions para devolver el elemento seleccionado <option>. Entonces usamos el atributo de este elemento data-name, encontrando el objeto SpeechSynthesisVoice cuyo nombre coincida con el valor del atributo. Y configuramos la propiedad de SpeechSynthesisUtterance.voice con el valor que coincida con la opción seleccionada.
Por último, configuramos SpeechSynthesisUtterance.pitch y SpeechSynthesisUtterance.rate con los valores de los elementos del formulario correspondientes. Entonces y ya configurado todo lo necesario, comenzamos la reproducción invocando SpeechSynthesis.speak(), y pasándolo a la instancia SpeechSynthesisUtterance como parámetro.
inputForm.onsubmit = function(event) {
event.preventDefault();
var utterThis = new SpeechSynthesisUtterance(inputTxt.value);
var selectedOption = voiceSelect.selectedOptions[0].getAttribute('data-name');
for(i = 0; i < voices.length ; i++) {
if(voices[i].name === selectedOption) {
utterThis.voice = voices[i];
}
}
utterThis.pitch = pitch.value;
utterThis.rate = rate.value;
synth.speak(utterThis);
Al final del manejador incluimos un manejador SpeechSynthesisUtterance.onpause para mostrar cómo usar SpeechSynthesisEvent. Cuando se invoca a SpeechSynthesis.pause(),este devuelve un mensaje informando del número y nombre del carácter en el que se detuvo la reproducción.
utterThis.onpause = function (event) {
var char = event.utterance.text.charAt(event.charIndex);
console.log(
"Speech paused at character " +
event.charIndex +
' of "' +
event.utterance.text +
'", which is "' +
char +
'".',
);
};
Por último, llamamos a blur() en la entrada de texto. Esto permite ocultar la entrada de texto en Firefox OS.
inputTxt.blur();
}
Actualizando los valores de tono y velocidad mostrados
La última parte del código simplemente actualiza los valores pitch/rate mostrados en la IU, cada vez que el slider cambia de posición.
pitch.onchange = function () {
pitchValue.textContent = pitch.value;
};
rate.onchange = function () {
rateValue.textContent = rate.value;
};