Streams API Konzepte
Die Streams API fügt dem Web-Framework eine sehr nützliche Sammlung von Werkzeugen hinzu und bietet Objekte, die es JavaScript ermöglichen, programmgesteuert auf Datenströme zuzugreifen, die über das Netzwerk empfangen werden, und diese nach Belieben des Entwicklers zu verarbeiten. Einige der mit Streams verbundenen Konzepte und Begriffe könnten Ihnen neu sein — dieser Artikel erklärt alles, was Sie wissen müssen.
Lesbare Streams
Ein lesbarer Stream ist eine Datenquelle, die in JavaScript durch ein ReadableStream-Objekt dargestellt wird und von einer zugrunde liegenden Quelle stammt — dies ist eine Ressource irgendwo im Netzwerk oder anderswo in Ihrer Domain, von der Sie Daten beziehen möchten.
Es gibt zwei Arten von zugrunde liegenden Quellen:
- Push-Quellen schieben ständig Daten an Sie, wenn Sie auf sie zugegriffen haben, und es liegt bei Ihnen, den Zugriff auf den Stream zu starten, zu pausieren oder abzubrechen. Beispiele sind Video-Streams und TCP/WebSockets.
- Pull-Quellen erfordern, dass Sie explizit Daten von ihnen anfordern, nachdem Sie verbunden sind. Beispiele sind ein Datei-Zugriffsvorgang über eine
fetch()-Anfrage.
Chunks
Die Daten werden sequenziell in kleinen Stücken, sogenannten Chunks, gelesen. Ein Chunk kann ein einzelnes Byte sein, oder etwas Größeres wie ein typisiertes Array einer bestimmten Größe. Ein einzelner Stream kann Chunks unterschiedlicher Größen und Typen enthalten.
Die in einem Stream platzierten Chunks werden als eingereiht bezeichnet — das bedeutet, dass sie in einer Warteschlange darauf warten, gelesen zu werden. Eine interne Warteschlange hält den Überblick über die Chunks, die noch nicht gelesen wurden (siehe den Abschnitt zu internen Warteschlangen und Warteschlangenstrategien unten).
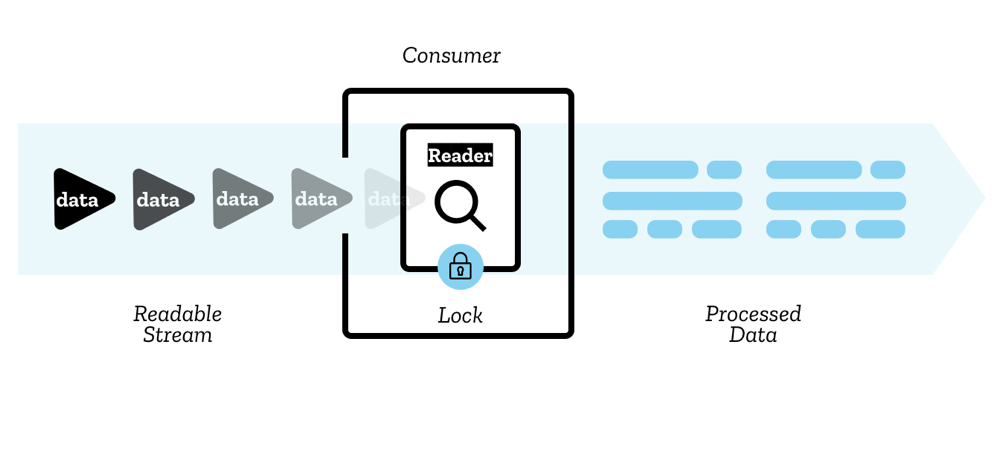
Leser, Verbraucher und Controller
Die Chunks im Inneren des Streams werden von einem Leser gelesen — dieser verarbeitet die Daten Stück für Stück und ermöglicht Ihnen, jede gewünschte Art von Operation darauf auszuführen. Der Leser plus der zusammenhängende Verarbeitungs-Code wird als Verbraucher bezeichnet.
Es gibt auch eine Konstruktion, die Sie nutzen werden, genannt Controller — jeder Leser hat einen zugehörigen Controller, der es Ihnen ermöglicht, den Stream zu kontrollieren (zum Beispiel ihn zu schließen, wenn gewünscht).
Sperren
Nur ein Leser kann einen Stream gleichzeitig lesen; wenn ein Leser erstellt wird und beginnt, einen Stream zu lesen (ein aktiver Leser), sagen wir, dass er daran gesperrt ist. Wenn Sie möchten, dass ein anderer Leser Ihren Stream liest, müssen Sie normalerweise den ersten Leser abbrechen, bevor Sie etwas anderes tun (obwohl Sie Streams auch aufteilen können, siehe den Abschnitt Teeing unten).
Lesbare Streams und Byte Streams
Beachten Sie, dass es zwei verschiedene Arten von lesbaren Streams gibt. Neben dem konventionellen lesbaren Stream gibt es einen Typ namens Byte Stream — dies ist eine erweiterte Version eines konventionellen Streams zum Lesen zugrundeliegender Byte-Quellen. Im Vergleich zum konventionellen lesbaren Stream dürfen Byte Streams von BYOB-Lesern gelesen werden (BYOB, "bring your own buffer"). Dieser Reader-Typ ermöglicht es, Streams direkt in einen vom Entwickler bereitgestellten Puffer zu lesen, was das erforderliche Kopieren minimiert. Welchen zugrunde liegenden Stream (und im weiteren Sinne, welche Leser und Controller) Ihr Code verwenden wird, hängt davon ab, wie der Stream ursprünglich erstellt wurde (siehe die Seite zum ReadableStream()-Konstruktor).
Sie können gebrauchsfertige lesbare Streams über Mechanismen wie ein Response.body einer Fetch-Anfrage nutzen oder Ihre eigenen Streams mit dem ReadableStream()-Konstruktor erstellen.
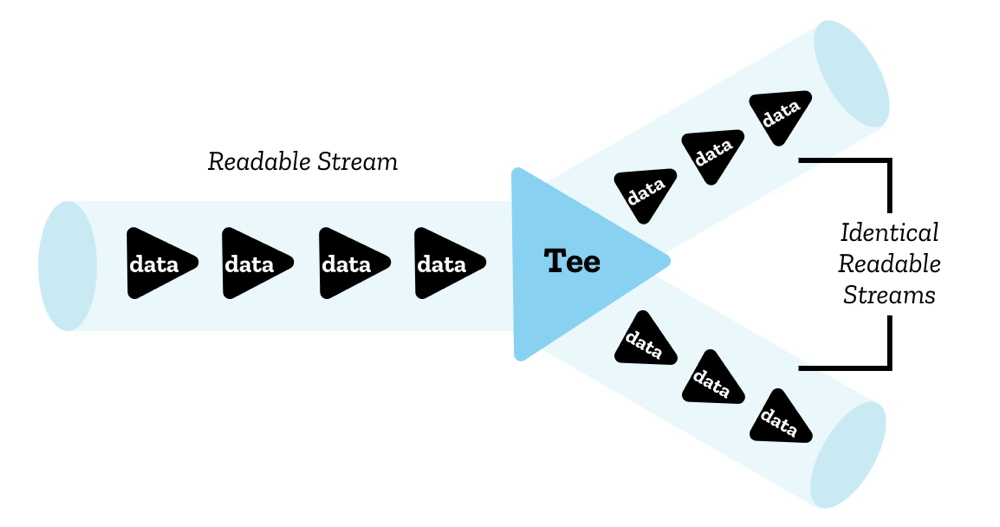
Teeing
Auch wenn nur ein einzelner Leser einen Stream gleichzeitig lesen kann, ist es möglich, einen Stream in zwei identische Kopien zu teilen, die dann von zwei separaten Lesern gelesen werden können. Dies wird als Teeing bezeichnet.
In JavaScript wird dies durch die Methode ReadableStream.tee() erreicht — sie gibt ein Array aus, das zwei identische Kopien des ursprünglichen lesbaren Streams enthält, die dann unabhängig voneinander von zwei separaten Lesern gelesen werden können.
Sie könnten dies zum Beispiel in einem ServiceWorker tun, wenn Sie eine Antwort vom Server abrufen und an den Browser streamen möchten, aber auch an den ServiceWorker-Cache streamen wollen. Da ein Antwortkörper nicht mehr als einmal konsumiert werden kann und ein Stream nicht mehr als von einem Leser gleichzeitig gelesen werden kann, benötigen Sie dazu zwei Kopien.
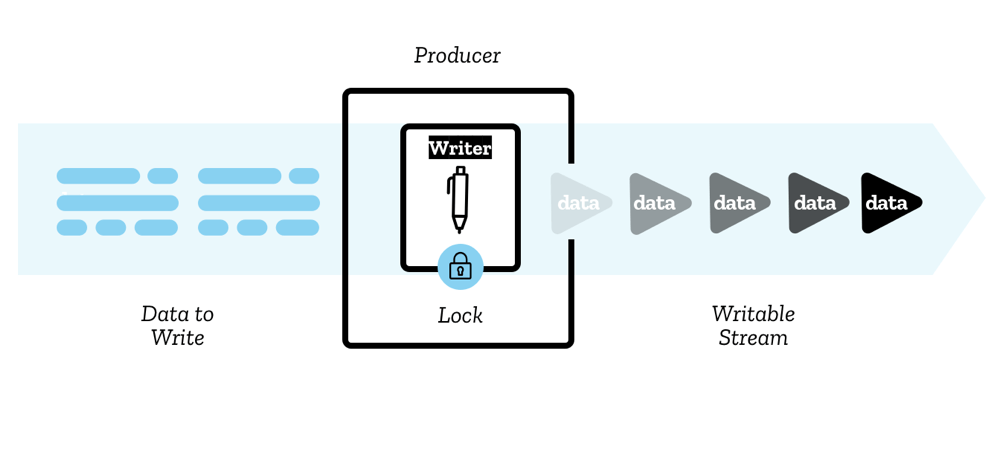
Schreibbare Streams
Ein schreibbarer Stream ist ein Ziel, in das Sie Daten schreiben können, dargestellt in JavaScript durch ein WritableStream-Objekt. Dies dient als Abstraktion über einem zugrunde liegenden Senke — einer I/O-Senke auf niedrigerer Ebene, in die Rohdaten geschrieben werden.
Die Daten werden über einen Schreiber an den Stream geschrieben, und zwar ein Chunk nach dem anderen. Ein Chunk kann viele Formen annehmen, genau wie die Chunks in einem Leser. Sie können beliebigen Code verwenden, um die zum Schreiben bereitstehenden Chunks zu erzeugen; der Schreiber plus der zugehörige Code wird als Produzent bezeichnet.
Wenn ein Schreiber erstellt wird und beginnt, in einen Stream zu schreiben (ein aktiver Schreiber), wird gesagt, dass er daran gesperrt ist. Nur ein Schreiber kann gleichzeitig in einen schreibbaren Stream schreiben. Wenn Sie möchten, dass ein anderer Schreiber in Ihren Stream zu schreiben beginnt, müssen Sie diesen normalerweise abbrechen, bevor Sie dann einen anderen Schreiber daran anhängen.
Eine interne Warteschlange verfolgt die Chunks, die in den Stream geschrieben, aber noch nicht von der zugrunde liegenden Senke verarbeitet wurden.
Es gibt auch eine Konstruktion, die Sie nutzen werden, genannt Controller — jeder Schreiber hat einen zugehörigen Controller, der es Ihnen ermöglicht, den Stream zu kontrollieren (zum Beispiel ihn abzubrechen, wenn gewünscht).
Sie können schreibbare Streams mit dem WritableStream()-Konstruktor verwenden. Diese haben derzeit eine sehr begrenzte Verfügbarkeit in Browsern.
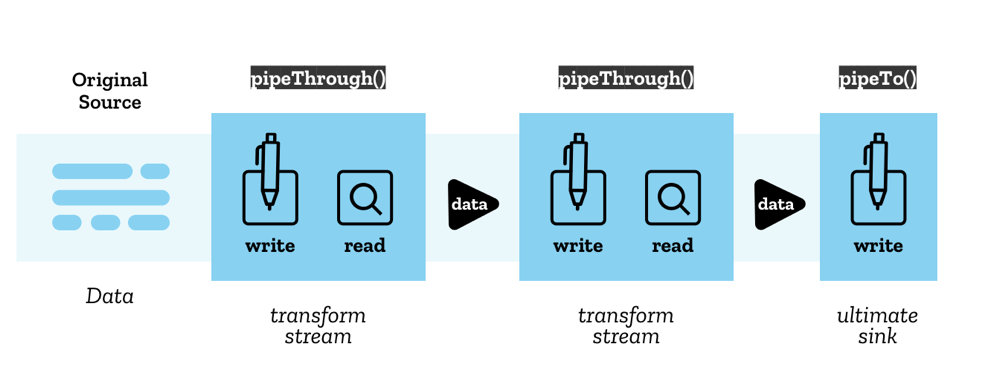
Pipe-Ketten
Die Streams API ermöglicht es, Streams durch eine Struktur, die als Pipe-Kette bezeichnet wird, ineinander zu leiten. Es gibt zwei Methoden, die dies erleichtern:
-
ReadableStream.pipeThrough()— leitet den Stream durch einen Transform-Stream, wobei möglicherweise das Datenformat verändert wird. Dies könnte verwendet werden, um Video-Frames zu kodieren oder zu dekodieren, Daten zu komprimieren oder zu dekomprimieren oder Daten anderweitig von einer Form in eine andere umzuwandeln.Ein Transform-Stream besteht aus einem Paar von Streams: einem lesbaren Stream, aus dem Daten gelesen werden, und einem schreibbaren Stream, in den sie geschrieben werden, zusammen mit geeigneten Mechanismen, um sicherzustellen, dass neue Daten verfügbar gemacht werden, sobald die Daten geschrieben wurden.
TransformStreamist eine konkrete Implementierung eines Transform-Streams, aber jedes Objekt, das dieselben lesbaren Stream- und schreibbaren Stream-Eigenschaften besitzt, kann anpipeThrough()übergeben werden. -
ReadableStream.pipeTo()— leitet an einen schreibbaren Stream, der als Endpunkt der Pipe-Kette fungiert.
Der Beginn der Pipe-Kette wird als ursprüngliche Quelle bezeichnet, und das Ende wird als endgültige Senke bezeichnet.
Rückstau
Ein wichtiges Konzept bei Streams ist der Rückstau — dies ist der Prozess, durch den ein einzelner Stream oder eine Pipe-Kette die Geschwindigkeit des Lesens/Schreibens reguliert. Wenn ein Stream später in der Kette noch beschäftigt ist und noch nicht bereit ist, weitere Chunks zu akzeptieren, sendet er ein Signal rückwärts durch die Kette, um den früheren Transform-Streams (oder der ursprünglichen Quelle) mitzuteilen, die Lieferung zu verlangsamen, um zu vermeiden, dass irgendwo ein Engpass entsteht.
Um Rückstau in einem ReadableStream zu verwenden, können wir den Controller nach der vom Verbraucher gewünschten Chunk-Größe fragen, indem wir die Eigenschaft ReadableStreamDefaultController.desiredSize am Controller abfragen. Wenn sie zu klein ist, kann unser ReadableStream seiner zugrunde liegenden Quelle sagen, dass sie aufhören soll, Daten zu senden, und wir üben Rückstau entlang der Stream-Kette aus.
Wenn der Verbraucher später erneut Daten empfangen möchte, können wir die Pull-Methode in der Stream-Erstellung verwenden, um unserer zugrunde liegenden Quelle mitzuteilen, unseren Stream mit Daten zu versorgen.
Interne Warteschlangen und Wartestrategien
Wie bereits erwähnt, werden die Chunks in einem Stream, die noch nicht verarbeitet und abgeschlossen wurden, von einer internen Warteschlange verfolgt.
- Im Fall von lesbaren Streams sind dies die Chunks, die eingereiht, aber noch nicht gelesen wurden
- Im Fall von schreibbaren Streams sind dies Chunks, die geschrieben, aber noch nicht von der zugrunde liegenden Senke verarbeitet wurden.
Interne Warteschlangen verwenden eine Warteschlangenstrategie, die bestimmt, wie Rückstau basierend auf dem Status der internen Warteschlange signalisiert wird.
Im Allgemeinen vergleicht die Strategie die Größe der Chunks in der Warteschlange mit einem Wert, der als High Water Mark bezeichnet wird, der die größte gesamte Chunk-Größe ist, die die Warteschlange verwalten möchte.
Die durchgeführte Berechnung ist
High Water Mark - Gesamtgröße der Chunks in der Warteschlange = gewünschte Größe
Die gewünschte Größe ist die Anzahl der Chunks, die der Stream noch akzeptieren kann, um den Stream fließen zu lassen, aber unter der High Water Mark in der Größe zu bleiben. Die Chunk-Erzeugung wird entsprechend verlangsamt/beschleunigt, um den Stream so schnell wie möglich fließen zu lassen, während die gewünschte Größe über null bleibt. Wenn der Wert auf null (oder darunter) fällt, bedeutet dies, dass Chunks schneller erzeugt werden als der Stream bewältigen kann, was zu Problemen führen kann.
Als Beispiel nehmen wir eine Chunk-Größe von 1 und eine High Water Mark von 3. Dies bedeutet, dass bis zu 3 Chunks eingereiht werden können, bevor die High Water Mark erreicht wird und Rückstau angewendet wird.